Apple ProRes overview
In this section, I will outline the principle of operation of the ProRes codec, focusing mostly on the relevant profiles (4444 and 4444 XQ). Most of the information here can be found within the aforementioned SMPTE document.
ProRes is an intra-codec, meaning each frame is encoded independently
from the others. This is great for video editing, because when jumping
around the video only a frame’s worth of data will be required, without
needing to process keyframes first. However, this means it doesn’t take
advantage of the temporal redundancies within the video stream, from
which a large part of the compression originates in inter-codecs.
It supports up to 8k resolution, 4:4:4 subsampling
(meaning the chroma planes are not downscaled compared to the luma
data), up to 12 bits of depth for luma and chroma, and an optional alpha
plane with up to 16 bits of depth.
Stream structure
A ProRes stream is constituted of several elements, or syntax structures, organised in a hierarchy:
- Frame header: one of the design goals of ProRes is fast random access, meaning that when seeking somewhere in the stream, there is little information to gather before decoding the actual frame. I’ve already mentioned how ProRes doesn’t do inter-prediction at all, but another consequence of this aim is that each frame must include all relevant metadata (dimensions, encoding parameters, color information, …).This is in contrast to H.264 or H.265, which try to minimise the amount of metadata sent during playback, by making frames inherit properties from a formerly signaled parameter set. This is packed into a frame header, which precedes the rest of the data.You may note that the ProRes stream doesn’t contain any frame timing information. This is left entirely to the container layer (eg. MXF).
- Picture header: a ProRes frame is divided into slices, which are essentially independent compression contexts. This helps with parallelism, because each of them can be decoded separately. The picture header contains information regarding the slice structure, including a slice table containing the offsets of the slices within the compressed bitstream.This is kept separate from the frame header for interlacing, in which a frame is made up of two interleaved, half-sized pictures (also called fields).
- Slice header: each slice includes its own slice header, informing the decoder of the compressed size of the luma and chroma plane, as well as a compression coefficient (the rescaling factor). Each slice contains a number of macroblocks (MB), which are 16x16 pixels large. Each MB is broken down further into 8x8 blocks. In 4:4:4 subsampling mode, a macroblock thus contains 4 luma and 4 chroma blocks. In addition, a picture can contain an optional alpha plane. If enabled, the alpha data will be packed after the color blocks (using a different compression scheme).
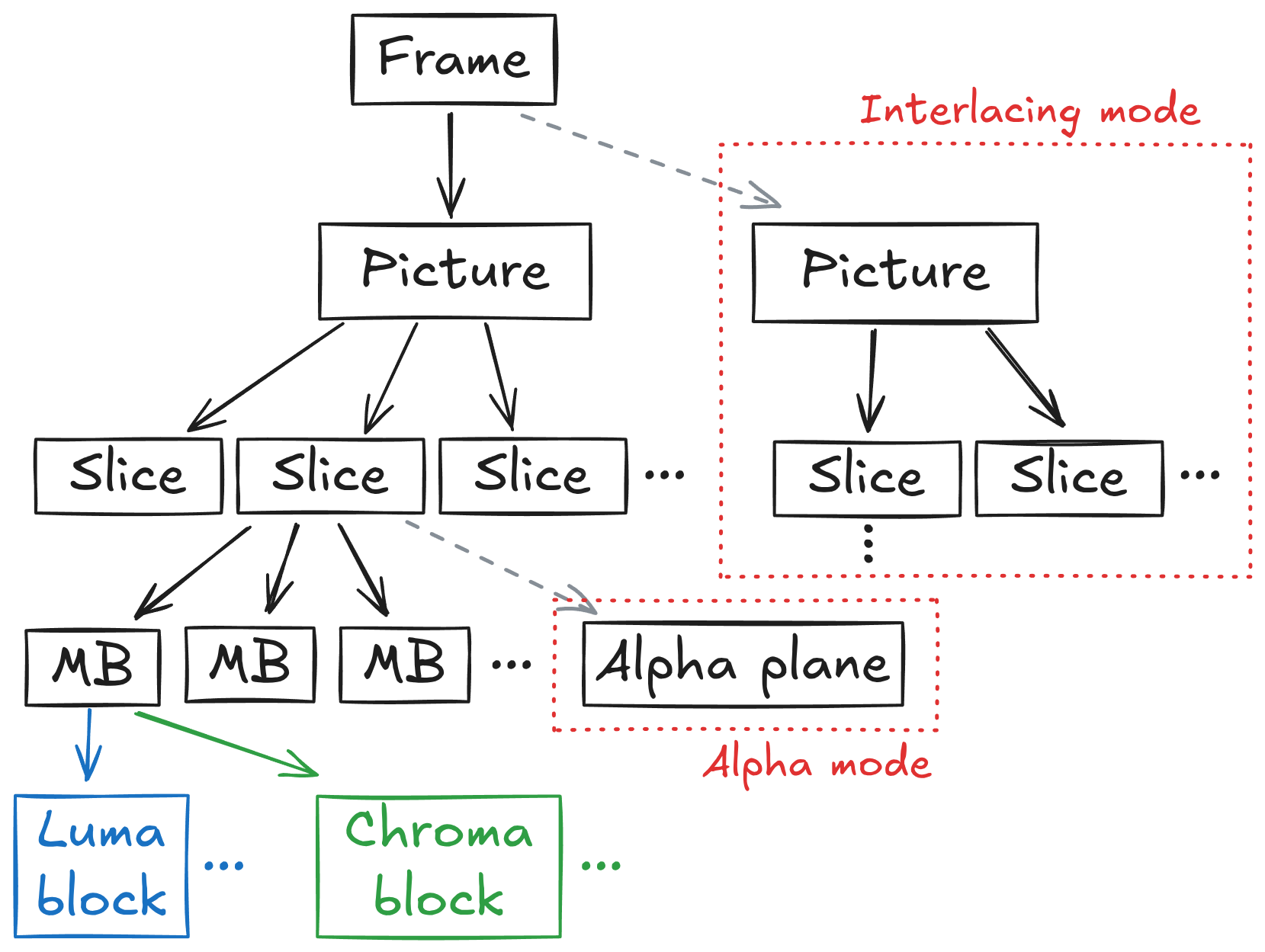 Figure
1: ProRes structure hierarchy
Figure
1: ProRes structure hierarchy
Picture structure
A ProRes picture is broken down into slices which can be decoded in
parallel, and contain a variable number of 16x16 MBs (up to 8). To this
end, the stream specifies a parameter in the picture header,
log2_desired_slice_size_in_mb. The picture data is then
tiled into slices of this size, starting from the left. If the picture
dimensions don’t exactly line up with the slice size, the remaining data
is broken down in slices of the largest power of two that still fits,
and this process is repeated recursively until the entire picture is
covered. If a picture dimension is not a multiple of 16, the encode will
slightly overshoot the picture size, and the stream consumer will have
to discard or ignore the data past the specified frame boundary.
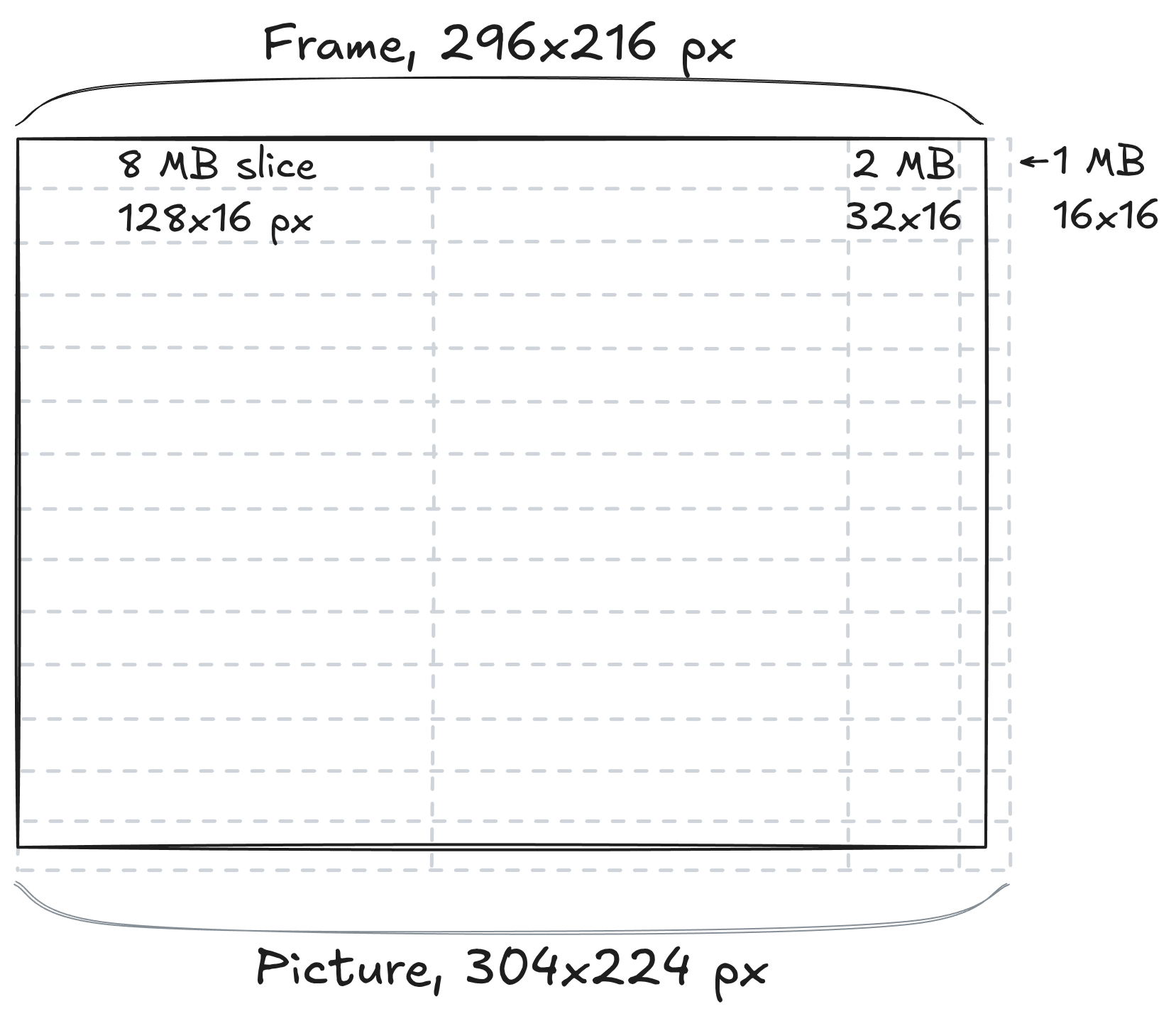 Figure
2: ProRes frame structure.
Figure
2: ProRes frame structure.
The frame width is 296 px, which is not a multiple of 16
().
Since the frame header signals
log2_desired_slice_size_in_mb = 3, the frame is first tiled
by 2 slices of 128 px
().
The closest power of two to the 40 px left
()
is 32, therefore the next slice contains 2 MBs. The final remainder is 8
px, so the last slice contains a single MB and the total picture size
overshoots by 8 px.
Similarly, the picture is tiled vertically into 14 slices
(),
and contains 8 extraneous pixels.
Slices can contain 1, 2, 4 or 8 macroblocks, arranged horizontally
(ie. 16x16, 32x16, 64x16, or 128x16 px). MBs are made up of 8x8 px
blocks, whose number depends on the subsampling scheme: there are always
4 luma blocks, but the number of chroma blocks can be 2 (for 4:2:2), or
4 (for 4:4:4). The chroma blocks are “stretched” in the final composite
image, to cover the same area as the
luma.Note
that this is not the job of the decoder, whose task is simply to
reconstruct the raw data contained within a compressed bitstream.
In our case, the profiles we care about use 4:4:4 subsampling, ie. no
chroma downscaling. 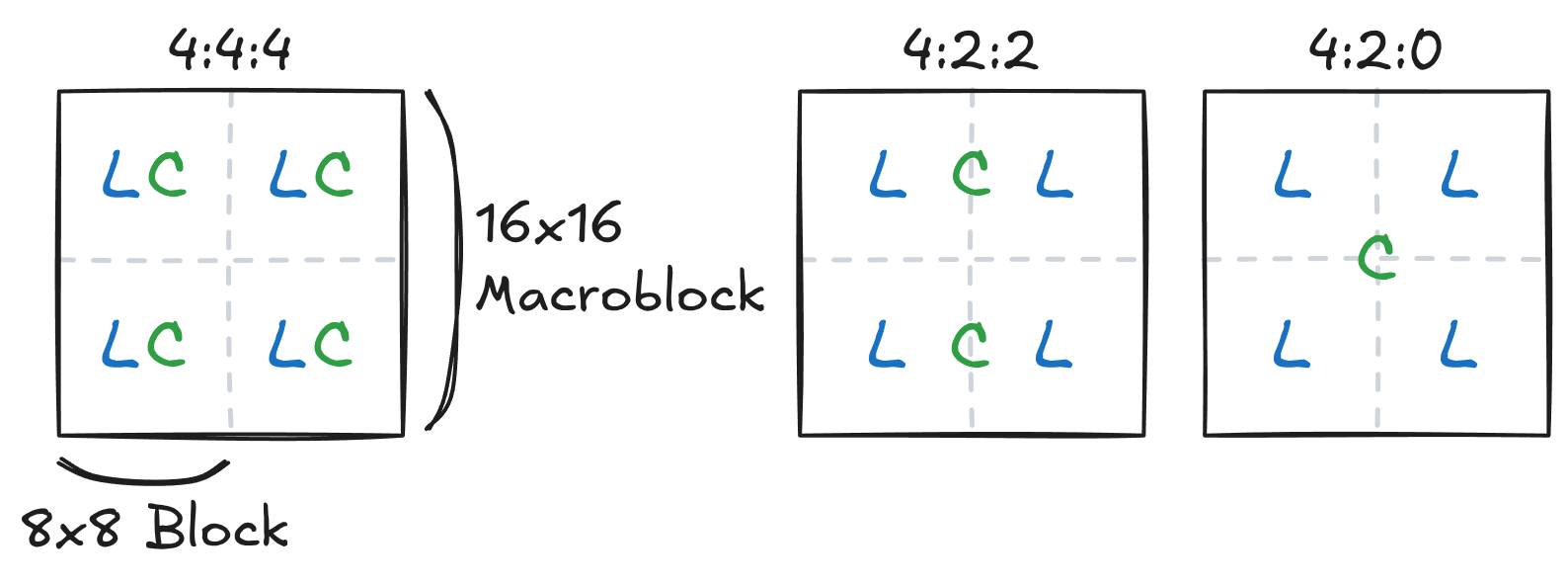 Figure
3: Luma and chroma sample locations for common subsampling
schemes.
Figure
3: Luma and chroma sample locations for common subsampling
schemes.
In 4:4:4 mode, each luma sample is associated a single chroma
sample.
In 4:2:2 mode, each luma sample is associated 2x1 chroma samples
(horizontal stretching).
In 4:2:0 mode, each luma sample is associated 2x2 chroma samples
(horizontal and vertical stretching). Note that ProRes does not support
4:2:0.
Entropy coding
Entropy coding turns a sequence of fixed-width signed integers (the
DCT coefficients) into a bitstream of variable-width codes.
ProRes uses a mix of the Golomb-Rice
and exp-Golomb
coding schemes, where small values are encoded with the former, and
larger with the latter
method.This
favors decode speed, as the encoded DCT coefficients are mostly small in
magnitude, and Golomb-Rice is computationally simpler than
exp-Golomb. The scheme and the Rice/exp-Golomb threshold being
used is determined according to the type of coefficient being encoded
(DC/AC),The
very first DCT coefficient (in the top-left corner of the transformed
matrix) is often called “DC”, because it corresponds to a null
frequency, and therefore represents a flat color over the whole spatial
domain. Other coefficients are termed “AC”. its position within
the bitstream (eg. whether it the first DC coefficient), and the
magnitude of the coefficient that came before it.
Inverse scanning
The decoded coefficients have been packed in a way that increases
entropy compression efficiency. The decoder must therefore rearrange
them in the intended spatial order before proceeding.
The coefficients are placed in the stream essentially in a bottom-up
direction with regards to the frame structure: each coefficient is
grouped with its peers from other blocks, then other
macroblocks.This
is similar to the so-called progressive encoding scheme for JPEG, which
encodes a given coefficient position for all blocks before moving to the
next. In addition, coefficients within blocks are scanned using a
weird mix of a Morton
curve pattern for the first 4x4 coefficients, and a zigzag
pattern for the rest, which resembles the pattern used in JPEG and
early MPEG codecs. The whole scan curve is illustrated in the
5th block in the figure below. 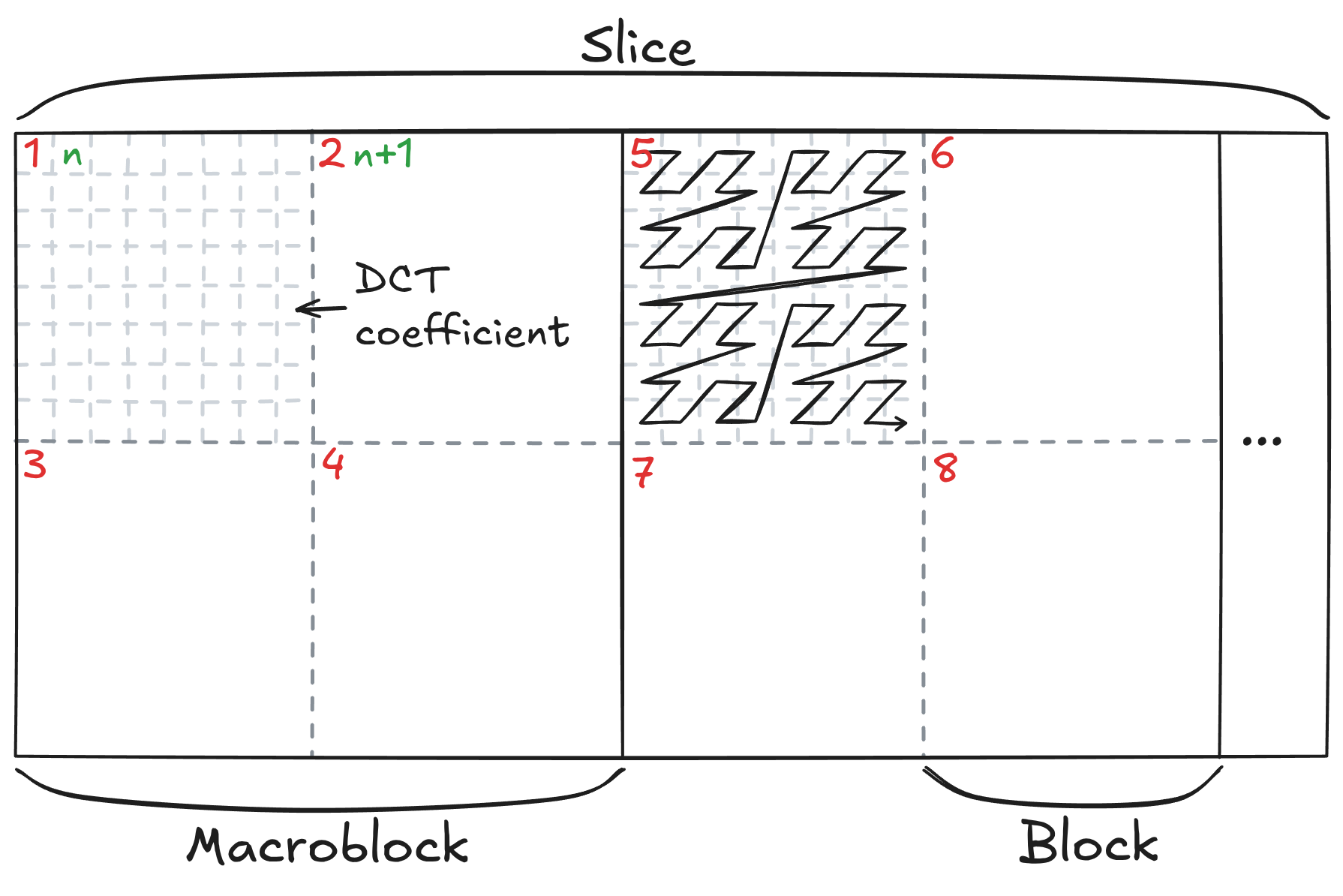 Figure
4: Scanning order for luma DCT coefficients
Figure
4: Scanning order for luma DCT coefficients
Red numbers indicate the first coefficients in the scanned stream, and
their spatial position. Green numbers represent the second coefficients,
and so on.
These reorderings result in a greatly increased locality and reduced entropy, by grouping together coefficients whose value is likely to be close. Indeed, spatial variations over the image tend to be small, and DCT coefficients typically have a decreasing magnitude when moving away from the top-left corner (the DC coefficient).I haven’t been able to come up with an explanation for this mix. It seems inferior to just using a zigzag curve, which more accurately represents the usual layout of DCT coefficients. It might be that the ProRes designers were aiming at a deliberate departure from the JPEG/MPEG standards, for copyright/patent reasons.
Note also that the block scanning is different for chroma blocks, and goes vertically within the macroblock instead of horizontally like above. This is likely so that the scanning pattern is identical for 4:2:2 and 4:4:4 subsampling.
Finally, the scan pattern transposed for interlaced pictures, improving its vertical locality.
Scaling and transform
Reordering yields quantised coefficients
organised in 8x8 frequency-domain blocks. Quantisation is the main
source of compression in ProRes, and in effect is performed by a simple
rounding division of the original matrix. To retrieve the de-quantised
block, the inverse operation is performed, by multiplying with a global
weight matrix
.
While the
matrix is global for the whole
frame,While
the weight matrix is global, it can be different for the luma and chroma
components. It can also be set to the default one, in which case all its
64 components are 4. it is paired with a scalar, the rescaling
factor
,
which is signaled per-slice.
The rescaling operation is therefore:
.
The coefficients are then transformed from the frequency domain to the spatial domain . This is achieved using the inverse discrete cosine transform (iDCT), with the expression given below.Note the similarity with the 2D Fourier transform. The sum range from 0 to 7 since the blocks are 8 px large, and produces a matrix of the same dimensions.While this operation (and in particular the nested sum) may seem intensive, there are clever ways of computing it rather efficiently.
with
After this operation, the decoding operation for luma and chroma components is essentially complete.There are a few steps remaining in order to calculate the final integer pixel data, and to output it at the correct location within the frame, but those are not particularly noteworthy.
Alpha plane
If present, the alpha data is encoded losslessly and without
subsampling, in raster-scanned order.
The data is differentially encoded using RLE,
meaning the difference of the current alpha value against the former
gets encoded, and identical consecutive values are sent only once, along
with the number of times they are repeated. For both the run lengths and
the alpha delta, pre-defined tables are used to represent common small
values using fewer bits.