Binary decompilation
Disassembly
NVIDIA provides a variety of tools capable of extracting the SASS
(Streaming ASSembler) instruction stream from a compiled CUDA kernel.
While cuobjdump and even Nsight compute can do it, I used
nvdisasm,I
used options -plr when disassabling to a text dump, and
-cfg for generating control flow graphs. in
particular for its ability to generate control flow graphs (CFG) of the
programs, which can then be rendered using dot. These CFGs
are reproduced below, along with the assembly listing:
 Figure
1: SASS control flow graph for each kernel
Figure
1: SASS control flow graph for each kernel
Complete listings:
jpegparse_pass1
//--------------------- .text.jpegparse_pass1 --------------------------
.section .text.jpegparse_pass1,"ax",@progbits
.sectionflags @"SHF_BARRIERS=1"
.sectioninfo @"SHI_REGISTERS=18"
.align 128
.global jpegparse_pass1
.type jpegparse_pass1,@function
.size jpegparse_pass1,(.L_x_59 - jpegparse_pass1)
.other jpegparse_pass1,@"STO_CUDA_ENTRY STV_DEFAULT"
jpegparse_pass1:
.text.jpegparse_pass1:
/*0000*/ IMAD.MOV.U32 R1, RZ, RZ, c[0x0][0x28] ;
/*0010*/ S2R R6, SR_CTAID.X ;
/*0020*/ ULDC UR5, c[0x0][0x170] ;
/*0030*/ BSSY B0, `(.L_x_17) ;
/*0040*/ UIADD3 UR4, UR5, 0xffff, URZ ;
/*0050*/ S2R R5, SR_TID.X ;
/*0060*/ UIADD3 UR5, UR5, -0x1, URZ ;
/*0070*/ IMAD.MOV.U32 R3, RZ, RZ, RZ ;
/*0080*/ USHF.R.U32.HI UR4, URZ, 0x10, UR4 ;
/*0090*/ ULDC.64 UR6, c[0x0][0x118] ;
/*00a0*/ UISETP.LT.U32.AND UP0, UPT, UR4, 0x4, UPT ;
/*00b0*/ USEL UR4, UR4, 0x4, !UP0 ;
/*00c0*/ IMAD R0, R6.reuse, 0x100, R5 ;
/*00d0*/ LOP3.LUT P0, RZ, R6, R5, RZ, 0xfc, !PT ;
/*00e0*/ IMAD R4, R0, UR4, RZ ;
/*00f0*/ SEL R10, RZ, 0x1, P0 ;
/*0100*/ IADD3 R2, R4, UR4, RZ ;
/*0110*/ IMNMX R7, R2, UR5, PT ;
/*0120*/ ISETP.GE.AND P1, PT, R7, R4, PT ;
/*0130*/ @!P1 BRA `(.L_x_18) ;
/*0140*/ IADD3 R2, -R4, 0x1, R7 ;
/*0150*/ IMAD.IADD R7, R7, 0x1, -R4 ;
/*0160*/ BSSY B1, `(.L_x_19) ;
/*0170*/ IMAD.MOV.U32 R8, RZ, RZ, RZ ;
/*0180*/ LOP3.LUT R2, R2, 0x3, RZ, 0xc0, !PT ;
/*0190*/ IMAD.MOV.U32 R3, RZ, RZ, RZ ;
/*01a0*/ ISETP.GE.U32.AND P0, PT, R7, 0x3, PT ;
/*01b0*/ ISETP.NE.AND P2, PT, R2, RZ, PT ;
/*01c0*/ @!P0 BRA `(.L_x_20) ;
/*01d0*/ IADD3 R3, R0, 0x1, RZ ;
/*01e0*/ ULDC UR5, c[0x0][0x170] ;
/*01f0*/ IADD3.X R6, P0, R4.reuse, c[0x0][0x160], RZ, PT, !PT ;
/*0200*/ UIADD3 UR5, -UR5, URZ, URZ ;
/*0210*/ IMAD.MOV.U32 R8, RZ, RZ, RZ ;
/*0220*/ IMAD R3, R3, UR4, RZ ;
/*0230*/ LEA.HI.X.SX32 R9, R4, c[0x0][0x164], 0x1, P0 ;
/*0240*/ LOP3.LUT R3, RZ, R3, RZ, 0x33, !PT ;
/*0250*/ IMNMX R7, R3, UR5, !PT ;
/*0260*/ IMAD.MOV.U32 R3, RZ, RZ, RZ ;
/*0270*/ IMAD.IADD R15, R2, 0x1, R7 ;
.L_x_21:
/*0280*/ IMAD.MOV.U32 R7, RZ, RZ, R9 ;
/*0290*/ LDG.E.U8 R14, [R6.64+-0x1] ;
/*02a0*/ LDG.E.U8 R11, [R6.64] ;
/*02b0*/ LDG.E.U8 R12, [R6.64+0x1] ;
/*02c0*/ LOP3.LUT R9, R14, 0xf8, RZ, 0xc0, !PT ;
/*02d0*/ PRMT R9, R9, 0x9910, RZ ;
/*02e0*/ ISETP.NE.AND P0, PT, R9, 0xd0, PT ;
/*02f0*/ ISETP.EQ.AND P0, PT, R8, 0xff, !P0 ;
/*0300*/ LDG.E.U8 R8, [R6.64+0x2] ;
/*0310*/ LOP3.LUT R9, R11, 0xf8, RZ, 0xc0, !PT ;
/*0320*/ LOP3.LUT R13, R12, 0xf8, RZ, 0xc0, !PT ;
/*0330*/ PRMT R9, R9, 0x9910, RZ ;
/*0340*/ PRMT R13, R13, 0x9910, RZ ;
/*0350*/ ISETP.NE.AND P1, PT, R9, 0xd0, PT ;
/*0360*/ IADD3 R9, R10, 0x1, RZ ;
/*0370*/ @!P0 IMAD.MOV R9, RZ, RZ, R10 ;
/*0380*/ ISETP.EQ.AND P1, PT, R14, 0xff, !P1 ;
/*0390*/ ISETP.NE.AND P3, PT, R13, 0xd0, PT ;
/*03a0*/ ISETP.EQ.AND P0, PT, R10, RZ, P0 ;
/*03b0*/ IADD3 R10, R9.reuse, 0x1, RZ ;
/*03c0*/ ISETP.EQ.AND P4, PT, R9, RZ, P1 ;
/*03d0*/ @!P1 IMAD.MOV R10, RZ, RZ, R9 ;
/*03e0*/ ISETP.EQ.AND P1, PT, R11, 0xff, !P3 ;
/*03f0*/ @P0 IADD3 R3, R4, 0x1, RZ ;
/*0400*/ ISETP.EQ.AND P3, PT, R10, RZ, P1 ;
/*0410*/ @P4 IADD3 R3, R4, 0x2, RZ ;
/*0420*/ IADD3 R11, R10, 0x1, RZ ;
/*0430*/ IADD3 R6, P4, R6, 0x4, RZ ;
/*0440*/ @!P1 IMAD.MOV R11, RZ, RZ, R10 ;
/*0450*/ @P3 IADD3 R3, R4.reuse, 0x3, RZ ;
/*0460*/ IADD3 R4, R4, 0x4, RZ ;
/*0470*/ IADD3 R10, R11, 0x1, RZ ;
/*0480*/ LOP3.LUT R9, R8, 0xf8, RZ, 0xc0, !PT ;
/*0490*/ ISETP.NE.AND P0, PT, R9, 0xd0, PT ;
/*04a0*/ IMAD.IADD R9, R15, 0x1, R4 ;
/*04b0*/ ISETP.EQ.AND P0, PT, R12, 0xff, !P0 ;
/*04c0*/ ISETP.NE.AND P3, PT, R9, RZ, PT ;
/*04d0*/ IMAD.X R9, RZ, RZ, R7, P4 ;
/*04e0*/ ISETP.EQ.AND P1, PT, R11, RZ, P0 ;
/*04f0*/ SEL R3, R4, R3, P1 ;
/*0500*/ @!P0 IMAD.MOV R10, RZ, RZ, R11 ;
/*0510*/ @P3 BRA `(.L_x_21) ;
.L_x_20:
/*0520*/ BSYNC B1 ;
.L_x_19:
/*0530*/ @!P2 BRA `(.L_x_18) ;
/*0540*/ IADD3 R6, P0, R4.reuse, c[0x0][0x160], RZ ;
/*0550*/ BSSY B1, `(.L_x_22) ;
/*0560*/ IMAD.MOV.U32 R9, RZ, RZ, R10 ;
/*0570*/ IADD3 R10, R4.reuse, 0x1, RZ ;
/*0580*/ LEA.HI.X.SX32 R7, R4, c[0x0][0x164], 0x1, P0 ;
.L_x_23:
/*0590*/ LDG.E.U8 R4, [R6.64] ;
/*05a0*/ IADD3 R2, R2, -0x1, RZ ;
/*05b0*/ ISETP.NE.AND P1, PT, R2, RZ, PT ;
/*05c0*/ IADD3 R6, P2, R6, 0x1, RZ ;
/*05d0*/ IMAD.X R7, RZ, RZ, R7, P2 ;
/*05e0*/ LOP3.LUT R11, R4, 0xf8, RZ, 0xc0, !PT ;
/*05f0*/ ISETP.NE.AND P0, PT, R11, 0xd0, PT ;
/*0600*/ IADD3 R11, R9, 0x1, RZ ;
/*0610*/ ISETP.EQ.AND P0, PT, R8, 0xff, !P0 ;
/*0620*/ IMAD.MOV.U32 R8, RZ, RZ, R4 ;
/*0630*/ @!P0 IMAD.MOV R11, RZ, RZ, R9 ;
/*0640*/ ISETP.EQ.AND P0, PT, R9, RZ, P0 ;
/*0650*/ IMAD.MOV.U32 R9, RZ, RZ, R11 ;
/*0660*/ SEL R3, R10.reuse, R3, P0 ;
/*0670*/ IADD3 R10, R10, 0x1, RZ ;
/*0680*/ @P1 BRA `(.L_x_23) ;
/*0690*/ BSYNC B1 ;
.L_x_22:
/*06a0*/ IMAD.MOV.U32 R10, RZ, RZ, R11 ;
.L_x_18:
/*06b0*/ BSYNC B0 ;
.L_x_17:
/*06c0*/ LOP3.LUT R2, R5.reuse, 0x1, RZ, 0xc0, !PT ;
/*06d0*/ STS [R5.X4], R10 ;
/*06e0*/ BAR.SYNC 0x0 ;
/*06f0*/ ISETP.NE.U32.AND P0, PT, R2, 0x1, PT ;
/*0700*/ IMAD.SHL.U32 R2, R5, 0x4, RZ ;
/*0710*/ R2P PR, R5, 0x7e ;
/*0720*/ @!P0 LOP3.LUT R4, R2.reuse, 0xfffffff8, RZ, 0xc0, !PT ;
/*0730*/ @!P0 LDS R6, [R5.X4] ;
/*0740*/ @P1 LOP3.LUT R8, R2.reuse, 0xfffffff0, RZ, 0xc0, !PT ;
/*0750*/ @!P0 LDS R7, [R4] ;
/*0760*/ @P2 LOP3.LUT R9, R2, 0xffffffe0, RZ, 0xc0, !PT ;
/*0770*/ @P1 LOP3.LUT R8, R8, 0x4, RZ, 0xfc, !PT ;
/*0780*/ @P2 LOP3.LUT R9, R9, 0xc, RZ, 0xfc, !PT ;
/*0790*/ @!P0 IMAD.IADD R6, R6, 0x1, R7 ;
/*07a0*/ @!P0 STS [R5.X4], R6 ;
/*07b0*/ BAR.SYNC 0x0 ;
/*07c0*/ @P1 LDS R8, [R8] ;
/*07d0*/ @P3 LOP3.LUT R6, R2, 0xffffffc0, RZ, 0xc0, !PT ;
/*07e0*/ LOP3.LUT P0, RZ, R5, 0x80, RZ, 0xc0, !PT ;
/*07f0*/ @P1 LDS R7, [R5.X4] ;
/*0800*/ @P3 LOP3.LUT R6, R6, 0x1c, RZ, 0xfc, !PT ;
/*0810*/ @P1 IMAD.IADD R10, R7, 0x1, R8 ;
/*0820*/ @P1 STS [R5.X4], R10 ;
/*0830*/ BAR.SYNC 0x0 ;
/*0840*/ @P2 LDS R9, [R9] ;
/*0850*/ @P4 LOP3.LUT R10, R2, 0xffffff80, RZ, 0xc0, !PT ;
/*0860*/ @P2 LDS R4, [R5.X4] ;
/*0870*/ @P4 LOP3.LUT R10, R10, 0x3c, RZ, 0xfc, !PT ;
/*0880*/ @P2 IMAD.IADD R4, R4, 0x1, R9 ;
/*0890*/ @P5 LOP3.LUT R9, R2, 0xffffff00, RZ, 0xc0, !PT ;
/*08a0*/ @P2 STS [R5.X4], R4 ;
/*08b0*/ @P5 LOP3.LUT R9, R9, 0x7c, RZ, 0xfc, !PT ;
/*08c0*/ BAR.SYNC 0x0 ;
/*08d0*/ @P3 LDS R6, [R6] ;
/*08e0*/ @P3 LDS R7, [R5.X4] ;
/*08f0*/ @P3 IMAD.IADD R8, R7, 0x1, R6 ;
/*0900*/ @P3 STS [R5.X4], R8 ;
/*0910*/ BAR.SYNC 0x0 ;
/*0920*/ @P4 LDS R10, [R10] ;
/*0930*/ @P4 LDS R7, [R5.X4] ;
/*0940*/ @P4 IMAD.IADD R4, R7, 0x1, R10 ;
/*0950*/ @P6 LOP3.LUT R7, R2, 0xfffffe00, RZ, 0xc0, !PT ;
/*0960*/ @P0 LOP3.LUT R2, R2, 0xfffffc00, RZ, 0xc0, !PT ;
/*0970*/ @P4 STS [R5.X4], R4 ;
/*0980*/ @P6 LOP3.LUT R7, R7, 0xfc, RZ, 0xfc, !PT ;
/*0990*/ BAR.SYNC 0x0 ;
/*09a0*/ @P5 LDS R9, [R9] ;
/*09b0*/ @P0 LOP3.LUT R4, R2, 0x1fc, RZ, 0xfc, !PT ;
/*09c0*/ @P5 LDS R6, [R5.X4] ;
/*09d0*/ @P5 IMAD.IADD R6, R6, 0x1, R9 ;
/*09e0*/ @P5 STS [R5.X4], R6 ;
/*09f0*/ BAR.SYNC 0x0 ;
/*0a00*/ @P6 LDS R7, [R7] ;
/*0a10*/ @P6 LDS R8, [R5.X4] ;
/*0a20*/ @P6 IMAD.IADD R8, R8, 0x1, R7 ;
/*0a30*/ IMAD.MOV.U32 R7, RZ, RZ, 0x8 ;
/*0a40*/ @P6 STS [R5.X4], R8 ;
/*0a50*/ IMAD.WIDE.U32 R6, R0, R7, c[0x0][0x168] ;
/*0a60*/ BAR.SYNC 0x0 ;
/*0a70*/ @P0 LDS R9, [R4] ;
/*0a80*/ @P0 LDS R2, [R5.X4] ;
/*0a90*/ @P0 IMAD.IADD R2, R2, 0x1, R9 ;
/*0aa0*/ @P0 STS [R5.X4], R2 ;
/*0ab0*/ @!P0 LDS R2, [R5.X4] ;
/*0ac0*/ STG.E.64 [R6.64], R2 ;
/*0ad0*/ EXIT ;
.L_x_24:
/*0ae0*/ BRA `(.L_x_24);
/*0af0*/ NOP;
/*0b00*/ NOP;
/*0b10*/ NOP;
/*0b20*/ NOP;
/*0b30*/ NOP;
/*0b40*/ NOP;
/*0b50*/ NOP;
/*0b60*/ NOP;
/*0b70*/ NOP;
.L_x_59:jpegparse_pass2
//--------------------- .text.jpegparse_pass2 --------------------------
.section .text.jpegparse_pass2,"ax",@progbits
.sectionflags @"SHF_BARRIERS=1"
.sectioninfo @"SHI_REGISTERS=15"
.align 128
.global jpegparse_pass2
.type jpegparse_pass2,@function
.size jpegparse_pass2,(.L_x_58 - jpegparse_pass2)
.other jpegparse_pass2,@"STO_CUDA_ENTRY STV_DEFAULT"
jpegparse_pass2:
.text.jpegparse_pass2:
/*0000*/ IMAD.MOV.U32 R1, RZ, RZ, c[0x0][0x28] ;
/*0010*/ S2R R9, SR_CTAID.X ;
/*0020*/ IMAD.MOV.U32 R7, RZ, RZ, 0x8 ;
/*0030*/ ULDC.64 UR4, c[0x0][0x118] ;
/*0040*/ IMAD.MOV.U32 R0, RZ, RZ, RZ ;
/*0050*/ S2R R11, SR_TID.X ;
/*0060*/ ISETP.GE.U32.AND P0, PT, R11, R9, PT ;
/*0070*/ @!P0 IMAD.SHL.U32 R2, R11, 0x100, RZ ;
/*0080*/ @!P0 IMAD.WIDE R2, R2, 0x8, RZ ;
/*0090*/ @!P0 LOP3.LUT R4, R2, 0x7f8, RZ, 0xfc, !PT ;
/*00a0*/ IMAD R2, R9, 0x100, R11 ;
/*00b0*/ @!P0 IADD3 R4, P1, R4, c[0x0][0x168], RZ ;
/*00c0*/ @!P0 IADD3.X R5, R3, c[0x0][0x16c], RZ, P1, !PT ;
/*00d0*/ IMAD.WIDE.U32 R2, R2, R7, c[0x0][0x168] ;
/*00e0*/ @!P0 LDG.E R0, [R4.64] ;
/*00f0*/ LDG.E.64 R2, [R2.64] ;
/*0100*/ ISETP.NE.AND P0, PT, R9, RZ, PT ;
/*0110*/ CS2R R6, SRZ ;
/*0120*/ ISETP.NE.AND P1, PT, R11, RZ, PT ;
/*0130*/ STS [R11.X4+0x400], R0 ;
/*0140*/ STS [R11.X4], R2 ;
/*0150*/ @!P0 BRA `(.L_x_0) ;
/*0160*/ IMAD.MOV.U32 R0, RZ, RZ, 0x1 ;
.L_x_1:
/*0170*/ BAR.SYNC 0x0 ;
/*0180*/ LOP3.LUT P2, RZ, R0, R11, RZ, 0xc0, !PT ;
/*0190*/ @P2 IADD3 R5, R0.reuse, -0x1, RZ ;
/*01a0*/ @P2 LDS R2, [R11.X4+0x400] ;
/*01b0*/ @P2 LOP3.LUT R5, R5, R11, R0, 0xf4, !PT ;
/*01c0*/ IMAD.SHL.U32 R0, R0, 0x2, RZ ;
/*01d0*/ @P2 LDS R5, [R5.X4+0x400] ;
/*01e0*/ @P2 IMAD.IADD R2, R2, 0x1, R5 ;
/*01f0*/ @P2 STS [R11.X4+0x400], R2 ;
/*0200*/ ISETP.GT.U32.AND P2, PT, R0, R9, PT ;
/*0210*/ @!P2 BRA `(.L_x_1) ;
.L_x_0:
/*0220*/ @P0 IMAD.SHL.U32 R9, R9, 0x4, RZ ;
/*0230*/ BAR.SYNC 0x0 ;
/*0240*/ @P0 LDS R6, [R9+0x3fc] ;
/*0250*/ @P1 LDS R7, [R11.X4+-0x4] ;
/*0260*/ LDS R0, [R11.X4] ;
/*0270*/ IMAD.IADD R6, R7, 0x1, R6 ;
/*0280*/ IMAD.IADD R0, R0, 0x1, -R7 ;
/*0290*/ ISETP.GE.U32.AND P0, PT, R6, c[0x0][0x178], PT ;
/*02a0*/ ISETP.LT.OR P0, PT, R0, 0x1, P0 ;
/*02b0*/ @P0 EXIT ;
/*02c0*/ IMAD R2, R0, 0x1800, R3 ;
/*02d0*/ LEA.HI.SX32 R5, R3, c[0x0][0x178], 0x1e ;
/*02e0*/ IMNMX.U32 R12, R2, c[0x0][0x17c], PT ;
/*02f0*/ IMAD.IADD R7, R6, 0x1, R5 ;
.L_x_15:
/*0300*/ IMAD.MOV.U32 R5, RZ, RZ, 0x4 ;
/*0310*/ ISETP.GE.AND P0, PT, R3, R12, PT ;
/*0320*/ BSSY B0, `(.L_x_2) ;
/*0330*/ CS2R R8, SRZ ;
/*0340*/ IMAD.WIDE R4, R6, R5, c[0x0][0x170] ;
/*0350*/ STG.E [R4.64], R7 ;
/*0360*/ @P0 BRA `(.L_x_3) ;
/*0370*/ IMAD.MOV.U32 R10, RZ, RZ, R3 ;
/*0380*/ CS2R R8, SRZ ;
.L_x_8:
/*0390*/ IADD3 R4, P0, R10, c[0x0][0x160], RZ ;
/*03a0*/ LEA.HI.X.SX32 R5, R10, c[0x0][0x164], 0x1, P0 ;
/*03b0*/ LDG.E.U8 R11, [R4.64] ;
/*03c0*/ IADD3 R3, R10, 0x1, RZ ;
/*03d0*/ BSSY B1, `(.L_x_4) ;
/*03e0*/ ISETP.NE.AND P0, PT, R11, 0xff, PT ;
/*03f0*/ ISETP.GE.OR P0, PT, R3, R12, P0 ;
/*0400*/ @P0 BRA `(.L_x_5) ;
/*0410*/ LDG.E.U8 R5, [R4.64+0x1] ;
/*0420*/ BSSY B2, `(.L_x_6) ;
/*0430*/ ISETP.NE.AND P0, PT, R5.reuse, RZ, PT ;
/*0440*/ LOP3.LUT R2, R5, 0xf8, RZ, 0xc0, !PT ;
/*0450*/ ISETP.NE.AND P1, PT, R2, 0xd0, PT ;
/*0460*/ @!P0 BRA `(.L_x_7) ;
/*0470*/ IADD3 R8, R8, 0x1, RZ ;
/*0480*/ IMAD.SHL.U32 R2, R9, 0x100, RZ ;
/*0490*/ ISETP.NE.AND P0, PT, R8, 0x4, PT ;
/*04a0*/ LOP3.LUT R9, R2, R11, RZ, 0xfc, !PT ;
/*04b0*/ IMAD.MOV.U32 R11, RZ, RZ, R5 ;
/*04c0*/ ISETP.GE.U32.OR P0, PT, R7, c[0x0][0x180], P0 ;
/*04d0*/ @!P0 IMAD.MOV.U32 R4, RZ, RZ, 0x4 ;
/*04e0*/ @!P0 IMAD.MOV.U32 R11, RZ, RZ, R5 ;
/*04f0*/ @!P0 IMAD.WIDE R2, R7.reuse, R4, c[0x0][0x170] ;
/*0500*/ @!P0 IADD3 R4, R7, 0x1, RZ ;
/*0510*/ @!P0 IMAD.MOV.U32 R8, RZ, RZ, RZ ;
/*0520*/ @!P0 STG.E [R2.64], R9 ;
/*0530*/ @!P0 IMAD.MOV.U32 R7, RZ, RZ, R4 ;
.L_x_7:
/*0540*/ BSYNC B2 ;
.L_x_6:
/*0550*/ @!P1 BREAK B1 ;
/*0560*/ IADD3 R3, R10, 0x2, RZ ;
/*0570*/ @!P1 BRA `(.L_x_3) ;
.L_x_5:
/*0580*/ BSYNC B1 ;
.L_x_4:
/*0590*/ IADD3 R8, R8, 0x1, RZ ;
/*05a0*/ IMAD.SHL.U32 R2, R9, 0x100, RZ ;
/*05b0*/ ISETP.GE.AND P1, PT, R3, R12, PT ;
/*05c0*/ IMAD.MOV.U32 R10, RZ, RZ, R3 ;
/*05d0*/ ISETP.NE.AND P0, PT, R8, 0x4, PT ;
/*05e0*/ LOP3.LUT R9, R2, R11, RZ, 0xfc, !PT ;
/*05f0*/ ISETP.GE.U32.OR P0, PT, R7, c[0x0][0x180], P0 ;
/*0600*/ @!P0 IMAD.MOV.U32 R4, RZ, RZ, 0x4 ;
/*0610*/ @!P0 IADD3 R2, R7.reuse, 0x1, RZ ;
/*0620*/ @!P0 IMAD.MOV.U32 R8, RZ, RZ, RZ ;
/*0630*/ @!P0 IMAD.WIDE R4, R7, R4, c[0x0][0x170] ;
/*0640*/ @!P0 IMAD.MOV.U32 R7, RZ, RZ, R2 ;
/*0650*/ @!P0 STG.E [R4.64], R9 ;
/*0660*/ @!P1 BRA `(.L_x_8) ;
.L_x_3:
/*0670*/ BSYNC B0 ;
.L_x_2:
/*0680*/ ISETP.NE.AND P0, PT, R8, RZ, PT ;
/*0690*/ BSSY B0, `(.L_x_9) ;
/*06a0*/ ISETP.GE.U32.OR P0, PT, R7, c[0x0][0x180], !P0 ;
/*06b0*/ @P0 BRA `(.L_x_10) ;
/*06c0*/ ISETP.GT.U32.AND P0, PT, R8, 0x3, PT ;
/*06d0*/ BSSY B1, `(.L_x_11) ;
/*06e0*/ @P0 BRA `(.L_x_12) ;
/*06f0*/ IMAD.MOV R2, RZ, RZ, -R8 ;
/*0700*/ IADD3 R8, -R8, 0x3, RZ ;
/*0710*/ BSSY B2, `(.L_x_13) ;
/*0720*/ LOP3.LUT R2, R2, 0x3, RZ, 0xc0, !PT ;
/*0730*/ ISETP.GE.U32.AND P0, PT, R8, 0x3, PT ;
/*0740*/ ISETP.NE.AND P1, PT, R2, RZ, PT ;
/*0750*/ @!P1 BRA `(.L_x_14) ;
/*0760*/ ISETP.NE.AND P1, PT, R2, 0x1, PT ;
/*0770*/ LEA R9, R9, 0xff, 0x8 ;
/*0780*/ @!P1 BRA `(.L_x_14) ;
/*0790*/ ISETP.NE.AND P1, PT, R2, 0x2, PT ;
/*07a0*/ LEA R9, R9, 0xff, 0x8 ;
/*07b0*/ @P1 LEA R9, R9, 0xff, 0x8 ;
.L_x_14:
/*07c0*/ BSYNC B2 ;
.L_x_13:
/*07d0*/ @!P0 BRA `(.L_x_12) ;
/*07e0*/ IMAD.MOV.U32 R9, RZ, RZ, -0x1 ;
.L_x_12:
/*07f0*/ BSYNC B1 ;
.L_x_11:
/*0800*/ IMAD.MOV.U32 R4, RZ, RZ, 0x4 ;
/*0810*/ IMAD.WIDE R4, R7.reuse, R4, c[0x0][0x170] ;
/*0820*/ IADD3 R7, R7, 0x1, RZ ;
/*0830*/ STG.E [R4.64], R9 ;
.L_x_10:
/*0840*/ BSYNC B0 ;
.L_x_9:
/*0850*/ IADD3 R6, R6, 0x1, RZ ;
/*0860*/ ISETP.GT.AND P1, PT, R0, 0x1, PT ;
/*0870*/ ISETP.GE.U32.AND P0, PT, R6, c[0x0][0x178], PT ;
/*0880*/ IADD3 R0, R0, -0x1, RZ ;
/*0890*/ @!P0 BRA P1, `(.L_x_15) ;
/*08a0*/ EXIT ;
.L_x_16:
/*08b0*/ BRA `(.L_x_16);
/*08c0*/ NOP;
/*08d0*/ NOP;
/*08e0*/ NOP;
/*08f0*/ NOP;
/*0900*/ NOP;
/*0910*/ NOP;
/*0920*/ NOP;
/*0930*/ NOP;
/*0940*/ NOP;
/*0950*/ NOP;
/*0960*/ NOP;
/*0970*/ NOP;
.L_x_58:jpegdec_vld
//--------------------- .text.jpegdec_vld --------------------------
.section .text.jpegdec_vld,"ax",@progbits
.sectioninfo @"SHI_REGISTERS=25"
.align 128
.global jpegdec_vld
.type jpegdec_vld,@function
.size jpegdec_vld,(.L_x_60 - jpegdec_vld)
.other jpegdec_vld,@"STO_CUDA_ENTRY STV_DEFAULT"
jpegdec_vld:
.text.jpegdec_vld:
/*0000*/ IMAD.MOV.U32 R1, RZ, RZ, c[0x0][0x28] ;
/*0010*/ S2R R7, SR_CTAID.X ;
/*0020*/ S2R R0, SR_TID.X ;
/*0030*/ IMAD R7, R7, 0x80, R0 ;
/*0040*/ ISETP.GE.AND P0, PT, R7, c[0x0][0x184], PT ;
/*0050*/ @P0 EXIT ;
/*0060*/ S2R R9, SR_CTAID.Y ;
/*0070*/ IADD3 R0, R7, c[0x0][0x180], RZ ;
/*0080*/ IMAD R0, R9, c[0x0][0x184], R0 ;
/*0090*/ TLD.SCR.LZ RZ, R0, R0, 0x0, 0x68, 1D, 0x1 ;
/*00a0*/ IADD3 R3, R0, 0x1, RZ ;
/*00b0*/ TLD.SCR.LZ RZ, R5, R0, 0x0, 0x68, 1D, 0x1 ;
/*00c0*/ TLD.SCR.LZ RZ, R3, R3, 0x0, 0x68, 1D, 0x1 ;
/*00d0*/ UMOV UR4, 0xf ;
/*00e0*/ IMAD.MOV.U32 R6, RZ, RZ, RZ ;
/*00f0*/ ULDC.64 UR8, c[0x0][0x190] ;
/*0100*/ ULOP3.LUT UR5, UR4, UR8, URZ, 0xc0, !UPT ;
/*0110*/ ULDC.64 UR6, c[0x0][0x188] ;
/*0120*/ ULOP3.LUT UR4, UR4, UR7, URZ, 0xc0, !UPT ;
/*0130*/ UIADD3 UR7, UR5, 0x1, URZ ;
/*0140*/ UIADD3 UR5, UR4, 0x1, URZ ;
/*0150*/ UIMAD UR6, UR7, UR6, URZ ;
/*0160*/ IMAD R4, R9, UR7, RZ ;
/*0170*/ IMAD.U32 R14, RZ, RZ, UR5 ;
/*0180*/ USHF.L.U32 UR5, UR9, 0xc, URZ ;
/*0190*/ IMAD R9, R4, c[0x0][0x184], R7 ;
/*01a0*/ IADD3 R0, R0, 0x2, RZ ;
/*01b0*/ IMAD R7, R7, R14, RZ ;
/*01c0*/ ULOP3.LUT UR5, UR5, 0x70000, URZ, 0xc0, !UPT ;
/*01d0*/ IMAD R2, R14, R9, RZ ;
/*01e0*/ ULDC.64 UR8, c[0x0][0x118] ;
/*01f0*/ IMAD.SHL.U32 R9, R2, 0x40, RZ ;
/*0200*/ IMAD R2, R14, c[0x0][0x184], RZ ;
/*0210*/ IMAD R9, R2, UR6, R9 ;
/*0220*/ IMAD.MOV.U32 R2, RZ, RZ, RZ ;
/*0230*/ IADD3 R8, R9, 0x40, RZ ;
.L_x_32:
/*0240*/ UIADD3 UR7, UR7, -0x1, URZ ;
/*0250*/ IMAD.MOV.U32 R9, RZ, RZ, R14 ;
/*0260*/ IMAD.MOV.U32 R11, RZ, RZ, R7 ;
/*0270*/ ISETP.NE.AND P0, PT, RZ, UR7, PT ;
.L_x_31:
/*0280*/ IADD3 R10, -R2.reuse, 0x20, RZ ;
/*0290*/ ULDC UR6, c[0x0][0x194] ;
/*02a0*/ SHF.L.U32 R13, R5, R2, RZ ;
/*02b0*/ USHF.L.U32 UR6, UR6, 0x10, URZ ;
/*02c0*/ SHF.R.U32.HI R10, RZ, R10, R3 ;
/*02d0*/ ISETP.NE.AND P1, PT, R2, RZ, PT ;
/*02e0*/ ULOP3.LUT UR6, UR6, 0x70000, URZ, 0xc0, !UPT ;
/*02f0*/ LOP3.LUT R10, R10, R13, RZ, 0xfc, !PT ;
/*0300*/ SEL R14, R5, R10, !P1 ;
/*0310*/ LEA.HI R10, R14, UR6, RZ, 0x10 ;
/*0320*/ TLD.SCR.LZ RZ, R10, R10, 0x0, 0x66, 1D, 0x1 ;
/*0330*/ IMAD.MOV.U32 R12, RZ, RZ, R3 ;
/*0340*/ SHF.R.U32.HI R15, RZ, 0x8, R10 ;
/*0350*/ LOP3.LUT R13, R10, 0xff, RZ, 0xc0, !PT ;
/*0360*/ SGXT.U32 R15, R15, 0x8 ;
/*0370*/ IADD3 R2, R15, R13, R2 ;
/*0380*/ ISETP.GE.U32.AND P1, PT, R2, 0x20, PT ;
/*0390*/ @P1 TLD.SCR.LZ RZ, R12, R0, 0x0, 0x68, 1D, 0x1 ;
/*03a0*/ LOP3.LUT P2, RZ, R10, 0xff, RZ, 0xc0, !PT ;
/*03b0*/ BSSY B0, `(.L_x_25) ;
/*03c0*/ SHF.L.U32 R16, R14, R15, RZ ;
/*03d0*/ IMAD.MOV.U32 R15, RZ, RZ, 0x4 ;
/*03e0*/ @P1 LOP3.LUT R2, R2, 0x1f, RZ, 0xc0, !PT ;
/*03f0*/ @P1 IMAD.MOV.U32 R5, RZ, RZ, R3 ;
/*0400*/ @P2 LOP3.LUT R14, RZ, R16, RZ, 0x33, !PT ;
/*0410*/ @P2 IADD3 R13, -R13, 0x20, RZ ;
/*0420*/ @P2 SHF.R.S32.HI R14, RZ, 0x1f, R14 ;
/*0430*/ @P2 SHF.R.U32.HI R10, RZ, R13.reuse, R16 ;
/*0440*/ IMAD.MOV.U32 R16, RZ, RZ, 0x1 ;
/*0450*/ @P2 SHF.R.U32.HI R13, RZ, R13, R14 ;
/*0460*/ IMAD.WIDE R14, R8, R15, c[0x0][0x160] ;
/*0470*/ @P2 IADD3 R6, -R13, R10, R6 ;
/*0480*/ IMAD.MOV.U32 R10, RZ, RZ, R8 ;
/*0490*/ IADD3 R13, R8, 0x1, RZ ;
/*04a0*/ IMAD.SHL.U32 R17, R6, 0x40, RZ ;
/*04b0*/ @P1 IADD3 R0, R0, 0x1, RZ ;
/*04c0*/ IMAD.MOV.U32 R8, RZ, RZ, R13 ;
/*04d0*/ STG.E [R14.64], R17 ;
/*04e0*/ IMAD.MOV.U32 R3, RZ, RZ, R12 ;
.L_x_30:
/*04f0*/ IADD3 R13, -R2.reuse, 0x20, RZ ;
/*0500*/ SHF.L.U32 R14, R5, R2, RZ ;
/*0510*/ SHF.R.U32.HI R13, RZ, R13, R12 ;
/*0520*/ ISETP.NE.AND P1, PT, R2, RZ, PT ;
/*0530*/ LOP3.LUT R14, R13, R14, RZ, 0xfc, !PT ;
/*0540*/ SEL R14, R5, R14, !P1 ;
/*0550*/ LEA.HI R13, R14, UR5, RZ, 0x10 ;
/*0560*/ TLD.SCR.LZ RZ, R13, R13, 0x0, 0x66, 1D, 0x1 ;
/*0570*/ SHF.R.U32.HI R15, RZ, 0x8, R13 ;
/*0580*/ LOP3.LUT R17, R13, 0xf, RZ, 0xc0, !PT ;
/*0590*/ SGXT.U32 R15, R15, 0x8 ;
/*05a0*/ IADD3 R2, R15, R17, R2 ;
/*05b0*/ ISETP.GE.U32.AND P1, PT, R2, 0x20, PT ;
/*05c0*/ @P1 TLD.SCR.LZ RZ, R3, R0, 0x0, 0x68, 1D, 0x1 ;
/*05d0*/ LOP3.LUT R19, R13, 0xff, RZ, 0xc0, !PT ;
/*05e0*/ @P1 IMAD.MOV.U32 R5, RZ, RZ, R12 ;
/*05f0*/ SHF.L.U32 R14, R14, R15, RZ ;
/*0600*/ ISETP.NE.AND P2, PT, R19.reuse, RZ, PT ;
/*0610*/ LEA.HI R19, R19, R16, RZ, 0x1c ;
/*0620*/ @P1 LOP3.LUT R2, R2, 0x1f, RZ, 0xc0, !PT ;
/*0630*/ @P1 IADD3 R0, R0, 0x1, RZ ;
/*0640*/ @!P2 BRA `(.L_x_26) ;
/*0650*/ ISETP.GT.U32.AND P1, PT, R19, 0x3f, PT ;
/*0660*/ @P1 BRA `(.L_x_27) ;
/*0670*/ LOP3.LUT P1, RZ, R13, 0xf, RZ, 0xc0, !PT ;
/*0680*/ BSSY B1, `(.L_x_28) ;
/*0690*/ @!P1 BRA `(.L_x_29) ;
/*06a0*/ LOP3.LUT R12, RZ, R14, RZ, 0x33, !PT ;
/*06b0*/ IMAD.MOV.U32 R15, RZ, RZ, 0x4 ;
/*06c0*/ IADD3 R17, -R17, 0x20, RZ ;
/*06d0*/ SHF.R.S32.HI R12, RZ, 0x1f, R12 ;
/*06e0*/ SHF.R.U32.HI R13, RZ, R17.reuse, R14 ;
/*06f0*/ SHF.R.U32.HI R12, RZ, R17, R12 ;
/*0700*/ IMAD.IADD R14, R13, 0x1, -R12 ;
/*0710*/ IMAD.WIDE R12, R8.reuse, R15, c[0x0][0x160] ;
/*0720*/ IADD3 R8, R8, 0x1, RZ ;
/*0730*/ IMAD R15, R14, 0x40, R19 ;
/*0740*/ STG.E [R12.64], R15 ;
.L_x_29:
/*0750*/ BSYNC B1 ;
.L_x_28:
/*0760*/ IADD3 R16, R19, 0x1, RZ ;
/*0770*/ IMAD.MOV.U32 R12, RZ, RZ, R3 ;
/*0780*/ ISETP.GE.U32.AND P1, PT, R16, 0x40, PT ;
/*0790*/ @!P1 BRA `(.L_x_30) ;
/*07a0*/ BRA `(.L_x_26) ;
.L_x_27:
/*07b0*/ S2R R12, SR_LANEID ;
/*07c0*/ VOTEU.ALL UR6, UPT, PT ;
/*07d0*/ IMAD.MOV.U32 R13, RZ, RZ, c[0x0][0x17c] ;
/*07e0*/ UFLO.U32 UR10, UR6 ;
/*07f0*/ POPC R15, UR6 ;
/*0800*/ ISETP.EQ.U32.AND P1, PT, R12, UR10, PT ;
/*0810*/ IMAD.MOV.U32 R12, RZ, RZ, c[0x0][0x178] ;
/*0820*/ @P1 RED.E.ADD.STRONG.GPU [R12.64], R15 ;
.L_x_26:
/*0830*/ BSYNC B0 ;
.L_x_25:
/*0840*/ UIADD3 UR6, UR4, 0x1, URZ ;
/*0850*/ LOP3.LUT R13, RZ, R10, RZ, 0x33, !PT ;
/*0860*/ IMAD.MOV.U32 R17, RZ, RZ, 0x4 ;
/*0870*/ IADD3 R9, R9, -0x1, RZ ;
/*0880*/ IMAD.U32 R14, RZ, RZ, UR6 ;
/*0890*/ ISETP.NE.AND P1, PT, R9, RZ, PT ;
/*08a0*/ IMAD R13, R10, 0x40, R13 ;
/*08b0*/ IMAD R12, R14, c[0x0][0x184], RZ ;
/*08c0*/ IMAD.IADD R15, R8, 0x1, R13 ;
/*08d0*/ IMAD R12, R12, R4, R11 ;
/*08e0*/ IADD3 R11, R11, 0x1, RZ ;
/*08f0*/ IADD3 R12, R12, 0x40, RZ ;
/*0900*/ IMAD.WIDE R12, R12, R17, c[0x0][0x160] ;
/*0910*/ STG.E [R12.64], R15 ;
/*0920*/ @P1 BRA `(.L_x_31) ;
/*0930*/ IADD3 R4, R4, 0x1, RZ ;
/*0940*/ @P0 BRA `(.L_x_32) ;
/*0950*/ S2R R7, SR_CTAID.X ;
/*0960*/ S2UR UR4, SR_CTAID.Y ;
/*0970*/ IMAD.MOV.U32 R4, RZ, RZ, c[0x0][0x190] ;
/*0980*/ ULDC UR5, c[0x0][0x194] ;
/*0990*/ S2R R8, SR_TID.X ;
/*09a0*/ IMAD.MOV.U32 R6, RZ, RZ, c[0x0][0x18c] ;
/*09b0*/ SHF.R.U32.HI R4, RZ, 0x8, R4 ;
/*09c0*/ SHF.R.U32.HI R6, RZ, 0x8, R6 ;
/*09d0*/ SGXT.U32 R4, R4, 0x4 ;
/*09e0*/ IADD3 R4, R4, 0x1, RZ ;
/*09f0*/ IMAD R12, R7, 0x80, R8 ;
/*0a00*/ SGXT.U32 R7, R6, 0x4 ;
/*0a10*/ IMAD R6, R4, UR4, RZ ;
/*0a20*/ USHF.L.U32 UR4, UR5, 0x8, URZ ;
/*0a30*/ IADD3 R7, R7, 0x1, RZ ;
/*0a40*/ IMAD R8, R6, c[0x0][0x184], R12 ;
/*0a50*/ USHF.L.U32 UR5, UR5, 0x4, URZ ;
/*0a60*/ ULOP3.LUT UR4, UR4, 0x70000, URZ, 0xc0, !UPT ;
/*0a70*/ IMAD R8, R7.reuse, R8, RZ ;
/*0a80*/ ULOP3.LUT UR5, UR5, 0x70000, URZ, 0xc0, !UPT ;
/*0a90*/ IMAD R9, R7, c[0x0][0x184], RZ ;
/*0aa0*/ IMAD.SHL.U32 R10, R8, 0x40, RZ ;
/*0ab0*/ IMAD R8, R4, c[0x0][0x188], RZ ;
/*0ac0*/ IMAD R11, R9, R8, R10 ;
/*0ad0*/ IMAD.MOV.U32 R8, RZ, RZ, RZ ;
/*0ae0*/ IMAD R10, R12, R7, RZ ;
/*0af0*/ IADD3 R11, R11, 0x40, RZ ;
.L_x_40:
/*0b00*/ IADD3 R4, R4, -0x1, RZ ;
/*0b10*/ IMAD R12, R9, R6, 0x40 ;
/*0b20*/ IMAD.MOV.U32 R13, RZ, RZ, R7 ;
/*0b30*/ ISETP.NE.AND P0, PT, R4, RZ, PT ;
/*0b40*/ IMAD.MOV.U32 R15, RZ, RZ, R10 ;
.L_x_39:
/*0b50*/ IADD3 R14, -R2, 0x20, RZ ;
/*0b60*/ SHF.L.U32 R17, R5, R2, RZ ;
/*0b70*/ SHF.R.U32.HI R14, RZ, R14, R3 ;
/*0b80*/ ISETP.NE.AND P1, PT, R2, RZ, PT ;
/*0b90*/ LOP3.LUT R14, R14, R17, RZ, 0xfc, !PT ;
/*0ba0*/ SEL R17, R5, R14, !P1 ;
/*0bb0*/ LEA.HI R14, R17, UR4, RZ, 0x10 ;
/*0bc0*/ TLD.SCR.LZ RZ, R14, R14, 0x0, 0x66, 1D, 0x1 ;
/*0bd0*/ IMAD.MOV.U32 R16, RZ, RZ, R3 ;
/*0be0*/ SHF.R.U32.HI R18, RZ, 0x8, R14 ;
/*0bf0*/ LOP3.LUT R19, R14, 0xff, RZ, 0xc0, !PT ;
/*0c00*/ SGXT.U32 R18, R18, 0x8 ;
/*0c10*/ IADD3 R2, R18, R19, R2 ;
/*0c20*/ ISETP.GE.U32.AND P1, PT, R2, 0x20, PT ;
/*0c30*/ @P1 TLD.SCR.LZ RZ, R16, R0, 0x0, 0x68, 1D, 0x1 ;
/*0c40*/ ISETP.NE.AND P2, PT, R19, RZ, PT ;
/*0c50*/ BSSY B0, `(.L_x_33) ;
/*0c60*/ SHF.L.U32 R21, R17, R18, RZ ;
/*0c70*/ @P1 IMAD.MOV.U32 R5, RZ, RZ, R3 ;
/*0c80*/ @P1 LOP3.LUT R2, R2, 0x1f, RZ, 0xc0, !PT ;
/*0c90*/ IMAD.MOV.U32 R20, RZ, RZ, 0x1 ;
/*0ca0*/ @P2 LOP3.LUT R17, RZ, R21, RZ, 0x33, !PT ;
/*0cb0*/ @P2 IADD3 R14, -R19, 0x20, RZ ;
/*0cc0*/ @P2 SHF.R.S32.HI R17, RZ, 0x1f, R17 ;
/*0cd0*/ @P2 SHF.R.U32.HI R18, RZ, R14.reuse, R21 ;
/*0ce0*/ @P2 SHF.R.U32.HI R17, RZ, R14, R17 ;
/*0cf0*/ IMAD.MOV.U32 R14, RZ, RZ, 0x4 ;
/*0d00*/ @P2 IADD3 R8, -R17, R18, R8 ;
/*0d10*/ IMAD.WIDE R18, R11.reuse, R14, c[0x0][0x168] ;
/*0d20*/ IADD3 R17, R11, 0x1, RZ ;
/*0d30*/ IMAD.SHL.U32 R21, R8, 0x40, RZ ;
/*0d40*/ @P1 IADD3 R0, R0, 0x1, RZ ;
/*0d50*/ IMAD.MOV.U32 R14, RZ, RZ, R11 ;
/*0d60*/ IMAD.MOV.U32 R11, RZ, RZ, R17 ;
/*0d70*/ STG.E [R18.64], R21 ;
/*0d80*/ IMAD.MOV.U32 R3, RZ, RZ, R16 ;
.L_x_38:
/*0d90*/ IADD3 R17, -R2, 0x20, RZ ;
/*0da0*/ SHF.L.U32 R18, R5, R2, RZ ;
/*0db0*/ SHF.R.U32.HI R17, RZ, R17, R16 ;
/*0dc0*/ ISETP.NE.AND P1, PT, R2, RZ, PT ;
/*0dd0*/ LOP3.LUT R18, R17, R18, RZ, 0xfc, !PT ;
/*0de0*/ SEL R18, R5, R18, !P1 ;
/*0df0*/ LEA.HI R17, R18, UR5, RZ, 0x10 ;
/*0e00*/ TLD.SCR.LZ RZ, R17, R17, 0x0, 0x66, 1D, 0x1 ;
/*0e10*/ SHF.R.U32.HI R19, RZ, 0x8, R17 ;
/*0e20*/ LOP3.LUT R22, R17, 0xf, RZ, 0xc0, !PT ;
/*0e30*/ SGXT.U32 R19, R19, 0x8 ;
/*0e40*/ IADD3 R2, R19, R22, R2 ;
/*0e50*/ ISETP.GE.U32.AND P1, PT, R2, 0x20, PT ;
/*0e60*/ @P1 TLD.SCR.LZ RZ, R3, R0, 0x0, 0x68, 1D, 0x1 ;
/*0e70*/ LOP3.LUT R21, R17, 0xff, RZ, 0xc0, !PT ;
/*0e80*/ @P1 IMAD.MOV.U32 R5, RZ, RZ, R16 ;
/*0e90*/ SHF.L.U32 R18, R18, R19, RZ ;
/*0ea0*/ ISETP.NE.AND P2, PT, R21.reuse, RZ, PT ;
/*0eb0*/ LEA.HI R20, R21, R20, RZ, 0x1c ;
/*0ec0*/ @P1 LOP3.LUT R2, R2, 0x1f, RZ, 0xc0, !PT ;
/*0ed0*/ @P1 IADD3 R0, R0, 0x1, RZ ;
/*0ee0*/ @!P2 BRA `(.L_x_34) ;
/*0ef0*/ ISETP.GT.U32.AND P1, PT, R20, 0x3f, PT ;
/*0f00*/ @P1 BRA `(.L_x_35) ;
/*0f10*/ ISETP.NE.AND P1, PT, R22, RZ, PT ;
/*0f20*/ BSSY B1, `(.L_x_36) ;
/*0f30*/ @!P1 BRA `(.L_x_37) ;
/*0f40*/ LOP3.LUT R16, RZ, R18, RZ, 0x33, !PT ;
/*0f50*/ IADD3 R17, -R22, 0x20, RZ ;
/*0f60*/ SHF.R.S32.HI R16, RZ, 0x1f, R16 ;
/*0f70*/ SHF.R.U32.HI R19, RZ, R17.reuse, R18 ;
/*0f80*/ IMAD.MOV.U32 R18, RZ, RZ, 0x4 ;
/*0f90*/ SHF.R.U32.HI R16, RZ, R17, R16 ;
/*0fa0*/ IMAD.IADD R19, R19, 0x1, -R16 ;
/*0fb0*/ IMAD.WIDE R16, R11.reuse, R18, c[0x0][0x168] ;
/*0fc0*/ IADD3 R11, R11, 0x1, RZ ;
/*0fd0*/ IMAD R19, R19, 0x40, R20 ;
/*0fe0*/ STG.E [R16.64], R19 ;
.L_x_37:
/*0ff0*/ BSYNC B1 ;
.L_x_36:
/*1000*/ IADD3 R20, R20, 0x1, RZ ;
/*1010*/ IMAD.MOV.U32 R16, RZ, RZ, R3 ;
/*1020*/ ISETP.GE.U32.AND P1, PT, R20, 0x40, PT ;
/*1030*/ @!P1 BRA `(.L_x_38) ;
/*1040*/ BRA `(.L_x_34) ;
.L_x_35:
/*1050*/ S2R R16, SR_LANEID ;
/*1060*/ VOTEU.ALL UR6, UPT, PT ;
/*1070*/ IMAD.MOV.U32 R17, RZ, RZ, c[0x0][0x17c] ;
/*1080*/ UFLO.U32 UR7, UR6 ;
/*1090*/ POPC R19, UR6 ;
/*10a0*/ ISETP.EQ.U32.AND P1, PT, R16, UR7, PT ;
/*10b0*/ IMAD.MOV.U32 R16, RZ, RZ, c[0x0][0x178] ;
/*10c0*/ @P1 RED.E.ADD.STRONG.GPU [R16.64], R19 ;
.L_x_34:
/*10d0*/ BSYNC B0 ;
.L_x_33:
/*10e0*/ LOP3.LUT R17, RZ, R14, RZ, 0x33, !PT ;
/*10f0*/ IMAD.IADD R16, R12, 0x1, R15 ;
/*1100*/ IADD3 R13, R13, -0x1, RZ ;
/*1110*/ IMAD.MOV.U32 R19, RZ, RZ, 0x4 ;
/*1120*/ IADD3 R15, R15, 0x1, RZ ;
/*1130*/ IMAD R14, R14, 0x40, R17 ;
/*1140*/ ISETP.NE.AND P1, PT, R13, RZ, PT ;
/*1150*/ IMAD.WIDE R16, R16, R19, c[0x0][0x168] ;
/*1160*/ IMAD.IADD R19, R11, 0x1, R14 ;
/*1170*/ STG.E [R16.64], R19 ;
/*1180*/ @P1 BRA `(.L_x_39) ;
/*1190*/ IADD3 R6, R6, 0x1, RZ ;
/*11a0*/ @P0 BRA `(.L_x_40) ;
/*11b0*/ S2R R6, SR_CTAID.X ;
/*11c0*/ S2UR UR4, SR_CTAID.Y ;
/*11d0*/ IMAD.MOV.U32 R4, RZ, RZ, c[0x0][0x190] ;
/*11e0*/ S2R R7, SR_TID.X ;
/*11f0*/ IMAD.MOV.U32 R8, RZ, RZ, c[0x0][0x18c] ;
/*1200*/ SHF.R.U32.HI R4, RZ, 0x10, R4 ;
/*1210*/ SHF.R.U32.HI R8, RZ, 0x10, R8 ;
/*1220*/ SGXT.U32 R4, R4, 0x4 ;
/*1230*/ IADD3 R4, R4, 0x1, RZ ;
/*1240*/ IMAD R12, R6, 0x80, R7 ;
/*1250*/ SGXT.U32 R7, R8, 0x4 ;
/*1260*/ IMAD R6, R4, UR4, RZ ;
/*1270*/ ULDC UR4, c[0x0][0x194] ;
/*1280*/ IADD3 R7, R7, 0x1, RZ ;
/*1290*/ IMAD R8, R6, c[0x0][0x184], R12 ;
/*12a0*/ USHF.R.U32.HI UR5, URZ, 0x4, UR4 ;
/*12b0*/ ULOP3.LUT UR4, UR4, 0x70000, URZ, 0xc0, !UPT ;
/*12c0*/ IMAD R8, R7.reuse, R8, RZ ;
/*12d0*/ ULOP3.LUT UR5, UR5, 0x70000, URZ, 0xc0, !UPT ;
/*12e0*/ IMAD R9, R7, c[0x0][0x184], RZ ;
/*12f0*/ IMAD.SHL.U32 R10, R8, 0x40, RZ ;
/*1300*/ IMAD R8, R4, c[0x0][0x188], RZ ;
/*1310*/ IMAD R11, R9, R8, R10 ;
/*1320*/ IMAD.MOV.U32 R8, RZ, RZ, RZ ;
/*1330*/ IMAD R10, R12, R7, RZ ;
/*1340*/ IADD3 R11, R11, 0x40, RZ ;
.L_x_48:
/*1350*/ IADD3 R4, R4, -0x1, RZ ;
/*1360*/ IMAD R12, R9, R6, 0x40 ;
/*1370*/ IMAD.MOV.U32 R13, RZ, RZ, R7 ;
/*1380*/ ISETP.NE.AND P0, PT, R4, RZ, PT ;
/*1390*/ IMAD.MOV.U32 R15, RZ, RZ, R10 ;
.L_x_47:
/*13a0*/ IADD3 R14, -R2, 0x20, RZ ;
/*13b0*/ SHF.L.U32 R17, R5, R2, RZ ;
/*13c0*/ SHF.R.U32.HI R14, RZ, R14, R3 ;
/*13d0*/ ISETP.NE.AND P1, PT, R2, RZ, PT ;
/*13e0*/ LOP3.LUT R14, R14, R17, RZ, 0xfc, !PT ;
/*13f0*/ SEL R17, R5, R14, !P1 ;
/*1400*/ LEA.HI R14, R17, UR4, RZ, 0x10 ;
/*1410*/ TLD.SCR.LZ RZ, R14, R14, 0x0, 0x66, 1D, 0x1 ;
/*1420*/ IMAD.MOV.U32 R16, RZ, RZ, R3 ;
/*1430*/ SHF.R.U32.HI R18, RZ, 0x8, R14 ;
/*1440*/ LOP3.LUT R19, R14, 0xff, RZ, 0xc0, !PT ;
/*1450*/ SGXT.U32 R18, R18, 0x8 ;
/*1460*/ IADD3 R2, R18, R19, R2 ;
/*1470*/ ISETP.GE.U32.AND P1, PT, R2, 0x20, PT ;
/*1480*/ @P1 TLD.SCR.LZ RZ, R16, R0, 0x0, 0x68, 1D, 0x1 ;
/*1490*/ ISETP.NE.AND P2, PT, R19, RZ, PT ;
/*14a0*/ BSSY B0, `(.L_x_41) ;
/*14b0*/ SHF.L.U32 R21, R17, R18, RZ ;
/*14c0*/ @P1 IMAD.MOV.U32 R5, RZ, RZ, R3 ;
/*14d0*/ @P1 LOP3.LUT R2, R2, 0x1f, RZ, 0xc0, !PT ;
/*14e0*/ IMAD.MOV.U32 R20, RZ, RZ, 0x1 ;
/*14f0*/ @P2 LOP3.LUT R17, RZ, R21, RZ, 0x33, !PT ;
/*1500*/ @P2 IADD3 R14, -R19, 0x20, RZ ;
/*1510*/ @P2 SHF.R.S32.HI R17, RZ, 0x1f, R17 ;
/*1520*/ @P2 SHF.R.U32.HI R18, RZ, R14.reuse, R21 ;
/*1530*/ @P2 SHF.R.U32.HI R17, RZ, R14, R17 ;
/*1540*/ IMAD.MOV.U32 R14, RZ, RZ, 0x4 ;
/*1550*/ @P2 IADD3 R8, -R17, R18, R8 ;
/*1560*/ IMAD.WIDE R18, R11.reuse, R14, c[0x0][0x170] ;
/*1570*/ IADD3 R17, R11, 0x1, RZ ;
/*1580*/ IMAD.SHL.U32 R21, R8, 0x40, RZ ;
/*1590*/ @P1 IADD3 R0, R0, 0x1, RZ ;
/*15a0*/ IMAD.MOV.U32 R14, RZ, RZ, R11 ;
/*15b0*/ IMAD.MOV.U32 R11, RZ, RZ, R17 ;
/*15c0*/ STG.E [R18.64], R21 ;
/*15d0*/ IMAD.MOV.U32 R3, RZ, RZ, R16 ;
.L_x_46:
/*15e0*/ IADD3 R17, -R2, 0x20, RZ ;
/*15f0*/ SHF.L.U32 R18, R5, R2, RZ ;
/*1600*/ SHF.R.U32.HI R17, RZ, R17, R16 ;
/*1610*/ ISETP.NE.AND P1, PT, R2, RZ, PT ;
/*1620*/ LOP3.LUT R18, R17, R18, RZ, 0xfc, !PT ;
/*1630*/ SEL R18, R5, R18, !P1 ;
/*1640*/ LEA.HI R17, R18, UR5, RZ, 0x10 ;
/*1650*/ TLD.SCR.LZ RZ, R17, R17, 0x0, 0x66, 1D, 0x1 ;
/*1660*/ SHF.R.U32.HI R19, RZ, 0x8, R17 ;
/*1670*/ LOP3.LUT R22, R17, 0xf, RZ, 0xc0, !PT ;
/*1680*/ SGXT.U32 R19, R19, 0x8 ;
/*1690*/ IADD3 R2, R19, R22, R2 ;
/*16a0*/ ISETP.GE.U32.AND P1, PT, R2, 0x20, PT ;
/*16b0*/ @P1 TLD.SCR.LZ RZ, R3, R0, 0x0, 0x68, 1D, 0x1 ;
/*16c0*/ LOP3.LUT R21, R17, 0xff, RZ, 0xc0, !PT ;
/*16d0*/ @P1 IMAD.MOV.U32 R5, RZ, RZ, R16 ;
/*16e0*/ SHF.L.U32 R18, R18, R19, RZ ;
/*16f0*/ ISETP.NE.AND P2, PT, R21.reuse, RZ, PT ;
/*1700*/ LEA.HI R20, R21, R20, RZ, 0x1c ;
/*1710*/ @P1 LOP3.LUT R2, R2, 0x1f, RZ, 0xc0, !PT ;
/*1720*/ @P1 IADD3 R0, R0, 0x1, RZ ;
/*1730*/ @!P2 BRA `(.L_x_42) ;
/*1740*/ ISETP.GT.U32.AND P1, PT, R20, 0x3f, PT ;
/*1750*/ @P1 BRA `(.L_x_43) ;
/*1760*/ ISETP.NE.AND P1, PT, R22, RZ, PT ;
/*1770*/ BSSY B1, `(.L_x_44) ;
/*1780*/ @!P1 BRA `(.L_x_45) ;
/*1790*/ LOP3.LUT R16, RZ, R18, RZ, 0x33, !PT ;
/*17a0*/ IADD3 R17, -R22, 0x20, RZ ;
/*17b0*/ SHF.R.S32.HI R16, RZ, 0x1f, R16 ;
/*17c0*/ SHF.R.U32.HI R19, RZ, R17.reuse, R18 ;
/*17d0*/ IMAD.MOV.U32 R18, RZ, RZ, 0x4 ;
/*17e0*/ SHF.R.U32.HI R16, RZ, R17, R16 ;
/*17f0*/ IMAD.IADD R19, R19, 0x1, -R16 ;
/*1800*/ IMAD.WIDE R16, R11.reuse, R18, c[0x0][0x170] ;
/*1810*/ IADD3 R11, R11, 0x1, RZ ;
/*1820*/ IMAD R19, R19, 0x40, R20 ;
/*1830*/ STG.E [R16.64], R19 ;
.L_x_45:
/*1840*/ BSYNC B1 ;
.L_x_44:
/*1850*/ IADD3 R20, R20, 0x1, RZ ;
/*1860*/ IMAD.MOV.U32 R16, RZ, RZ, R3 ;
/*1870*/ ISETP.GE.U32.AND P1, PT, R20, 0x40, PT ;
/*1880*/ @!P1 BRA `(.L_x_46) ;
/*1890*/ BRA `(.L_x_42) ;
.L_x_43:
/*18a0*/ S2R R16, SR_LANEID ;
/*18b0*/ VOTEU.ALL UR6, UPT, PT ;
/*18c0*/ IMAD.MOV.U32 R17, RZ, RZ, c[0x0][0x17c] ;
/*18d0*/ UFLO.U32 UR7, UR6 ;
/*18e0*/ POPC R19, UR6 ;
/*18f0*/ ISETP.EQ.U32.AND P1, PT, R16, UR7, PT ;
/*1900*/ IMAD.MOV.U32 R16, RZ, RZ, c[0x0][0x178] ;
/*1910*/ @P1 RED.E.ADD.STRONG.GPU [R16.64], R19 ;
.L_x_42:
/*1920*/ BSYNC B0 ;
.L_x_41:
/*1930*/ LOP3.LUT R17, RZ, R14, RZ, 0x33, !PT ;
/*1940*/ IMAD.IADD R16, R12, 0x1, R15 ;
/*1950*/ IADD3 R13, R13, -0x1, RZ ;
/*1960*/ IMAD.MOV.U32 R19, RZ, RZ, 0x4 ;
/*1970*/ IADD3 R15, R15, 0x1, RZ ;
/*1980*/ IMAD R14, R14, 0x40, R17 ;
/*1990*/ ISETP.NE.AND P1, PT, R13, RZ, PT ;
/*19a0*/ IMAD.WIDE R16, R16, R19, c[0x0][0x170] ;
/*19b0*/ IMAD.IADD R19, R11, 0x1, R14 ;
/*19c0*/ STG.E [R16.64], R19 ;
/*19d0*/ @P1 BRA `(.L_x_47) ;
/*19e0*/ IADD3 R6, R6, 0x1, RZ ;
/*19f0*/ @P0 BRA `(.L_x_48) ;
/*1a00*/ EXIT ;
.L_x_49:
/*1a10*/ BRA `(.L_x_49);
/*1a20*/ NOP;
/*1a30*/ NOP;
/*1a40*/ NOP;
/*1a50*/ NOP;
/*1a60*/ NOP;
/*1a70*/ NOP;
/*1a80*/ NOP;
/*1a90*/ NOP;
/*1aa0*/ NOP;
/*1ab0*/ NOP;
/*1ac0*/ NOP;
/*1ad0*/ NOP;
/*1ae0*/ NOP;
/*1af0*/ NOP;
.L_x_60:jpegdec_idct
//--------------------- .text.jpegdec_idct --------------------------
.section .text.jpegdec_idct,"ax",@progbits
.sectionflags @"SHF_BARRIERS=1"
.sectioninfo @"SHI_REGISTERS=22"
.align 128
.global jpegdec_idct
.type jpegdec_idct,@function
.size jpegdec_idct,(.L_x_61 - jpegdec_idct)
.other jpegdec_idct,@"STO_CUDA_ENTRY STV_DEFAULT"
jpegdec_idct:
.text.jpegdec_idct:
/*0000*/ MOV R1, c[0x0][0x28] ;
/*0010*/ S2R R6, SR_TID.X ;
/*0020*/ MOV R4, 0x24 ;
/*0030*/ BSSY B0, `(.L_x_50) ;
/*0040*/ LOP3.LUT R0, R6.reuse, 0x7, RZ, 0xc0, !PT ;
/*0050*/ LOP3.LUT R5, R6, 0xfffffff8, RZ, 0xc0, !PT ;
/*0060*/ ISETP.NE.AND P0, PT, R0, RZ, PT ;
/*0070*/ IMAD R3, R5, R4, 0x20 ;
/*0080*/ LEA R2, R0, R3, 0x2 ;
/*0090*/ SHF.R.U32.HI R3, RZ, 0x3, R6 ;
/*00a0*/ @P0 BRA `(.L_x_51) ;
/*00b0*/ S2R R6, SR_CTAID.X ;
/*00c0*/ S2UR UR4, SR_CTAID.Y ;
/*00d0*/ MOV R8, c[0x0][0x174] ;
/*00e0*/ LEA R7, R6, R3, 0x3 ;
/*00f0*/ USGXT UR4, UR4, 0x18 ;
/*0100*/ SGXT R6, R8, 0x18 ;
/*0110*/ IADD3 R7, R7, 0x40, RZ ;
/*0120*/ IMAD R6, R6, UR4, R7 ;
/*0130*/ TLD.SCR.LZ RZ, R6, R6, 0x0, 0x5e, 1D, 0x1 ;
/*0140*/ STS [R3.X4], R6 ;
.L_x_51:
/*0150*/ BSYNC B0 ;
.L_x_50:
/*0160*/ STS [R2], RZ ;
/*0170*/ BSSY B0, `(.L_x_52) ;
/*0180*/ STS [R2+0x24], RZ ;
/*0190*/ STS [R2+0x48], RZ ;
/*01a0*/ STS [R2+0x6c], RZ ;
/*01b0*/ STS [R2+0x90], RZ ;
/*01c0*/ STS [R2+0xb4], RZ ;
/*01d0*/ STS [R2+0xd8], RZ ;
/*01e0*/ STS [R2+0xfc], RZ ;
/*01f0*/ BAR.SYNC 0x0 ;
/*0200*/ LDS R6, [R3.X4] ;
/*0210*/ LOP3.LUT R7, R6, 0x3f, RZ, 0xc0, !PT ;
/*0220*/ SHF.R.U32.HI R9, RZ, 0x6, R6 ;
/*0230*/ ISETP.GT.U32.AND P0, PT, R0, R7, PT ;
/*0240*/ ISETP.EQ.OR P0, PT, R9, RZ, P0 ;
/*0250*/ @P0 BRA `(.L_x_53) ;
/*0260*/ ISETP.GE.U32.AND P2, PT, R0.reuse, R7, PT ;
/*0270*/ IADD3 R9, R0, R9, RZ ;
/*0280*/ @P2 TLD.SCR.LZ RZ, R6, R9, 0x0, 0x5e, 1D, 0x1 ;
/*0290*/ @P2 LOP3.LUT R10, R6, 0x3f, RZ, 0xc0, !PT ;
/*02a0*/ @P2 TLD.SCR.LZ RZ, R8, R10, 0x0, 0x5e, 1D, 0x1 ;
/*02b0*/ @P2 LDC.U8 R12, c[0x3][R10] ;
/*02c0*/ @P2 SHF.R.S32.HI R11, RZ, 0x6, R6 ;
/*02d0*/ BSSY B1, `(.L_x_54) ;
/*02e0*/ MOV R6, R0 ;
/*02f0*/ PLOP3.LUT P0, PT, P2, PT, PT, 0x8, 0x0 ;
/*0300*/ @P2 IADD3 R6, R6, 0x8, RZ ;
/*0310*/ @P2 IADD3 R9, R9, 0x8, RZ ;
/*0320*/ ISETP.GT.U32.AND P1, PT, R7, R6, PT ;
/*0330*/ @P2 LEA.HI R13, R12.reuse, R5, RZ, 0x1d ;
/*0340*/ @P2 SHF.L.U32 R12, R12, 0x2, RZ ;
/*0350*/ @P2 IMAD R13, R13, R4, 0x20 ;
/*0360*/ @P2 LOP3.LUT R12, R12, 0x1c, RZ, 0xc0, !PT ;
/*0370*/ @P2 IADD3 R12, R13, R12, RZ ;
/*0380*/ @P2 IMAD R8, R8, R11, RZ ;
/*0390*/ @P2 I2FP.F32.S32 R11, R8 ;
/*03a0*/ IADD3 R8, R7, -R6, RZ ;
/*03b0*/ @P2 FMUL R11, R11, 0.00390625 ;
/*03c0*/ ISETP.LE.U32.OR P1, PT, R8, 0x7, !P1 ;
/*03d0*/ @P2 STS [R12], R11 ;
/*03e0*/ @P1 BRA `(.L_x_55) ;
/*03f0*/ PLOP3.LUT P0, PT, PT, PT, PT, 0x8, 0x0 ;
/*0400*/ IADD3 R19, R7, -0x7, RZ ;
.L_x_56:
/*0410*/ IADD3 R14, R9, 0x8, RZ ;
/*0420*/ TLD.SCR.LZ RZ, R8, R9, 0x0, 0x5e, 1D, 0x1 ;
/*0430*/ TLD.SCR.LZ RZ, R14, R14, 0x0, 0x5e, 1D, 0x1 ;
/*0440*/ LOP3.LUT R10, R8, 0x3f, RZ, 0xc0, !PT ;
/*0450*/ LOP3.LUT R15, R14, 0x3f, RZ, 0xc0, !PT ;
/*0460*/ TLD.SCR.LZ RZ, R11, R10, 0x0, 0x5e, 1D, 0x1 ;
/*0470*/ TLD.SCR.LZ RZ, R16, R15, 0x0, 0x5e, 1D, 0x1 ;
/*0480*/ LDC.U8 R12, c[0x3][R10] ;
/*0490*/ SHF.R.S32.HI R8, RZ, 0x6, R8 ;
/*04a0*/ SHF.R.S32.HI R17, RZ, 0x6, R14 ;
/*04b0*/ IADD3 R6, R6, 0x10, RZ ;
/*04c0*/ IADD3 R9, R9, 0x10, RZ ;
/*04d0*/ ISETP.GE.U32.AND P1, PT, R6, R19, PT ;
/*04e0*/ LEA.HI R13, R12, R5, RZ, 0x1d ;
/*04f0*/ SHF.L.U32 R12, R12, 0x2, RZ ;
/*0500*/ IMAD R13, R13, R4, 0x20 ;
/*0510*/ LOP3.LUT R12, R12, 0x1c, RZ, 0xc0, !PT ;
/*0520*/ IADD3 R13, R13, R12, RZ ;
/*0530*/ LDC.U8 R12, c[0x3][R15] ;
/*0540*/ IMAD R8, R11, R8, RZ ;
/*0550*/ LEA.HI R11, R12.reuse, R5, RZ, 0x1d ;
/*0560*/ IMAD.SHL.U32 R12, R12, 0x4, RZ ;
/*0570*/ IMAD R16, R16, R17, RZ ;
/*0580*/ I2FP.F32.S32 R8, R8 ;
/*0590*/ IMAD R11, R11, R4, 0x20 ;
/*05a0*/ LOP3.LUT R12, R12, 0x1c, RZ, 0xc0, !PT ;
/*05b0*/ I2FP.F32.S32 R16, R16 ;
/*05c0*/ FMUL R8, R8, 0.00390625 ;
/*05d0*/ IADD3 R11, R11, R12, RZ ;
/*05e0*/ FMUL R16, R16, 0.00390625 ;
/*05f0*/ STS [R13], R8 ;
/*0600*/ STS [R11], R16 ;
/*0610*/ @!P1 BRA `(.L_x_56) ;
.L_x_55:
/*0620*/ BSYNC B1 ;
.L_x_54:
/*0630*/ ISETP.LE.U32.OR P0, PT, R6, R7, P0 ;
/*0640*/ @!P0 BRA `(.L_x_53) ;
/*0650*/ TLD.SCR.LZ RZ, R9, R9, 0x0, 0x5e, 1D, 0x1 ;
/*0660*/ LOP3.LUT R6, R9, 0x3f, RZ, 0xc0, !PT ;
/*0670*/ TLD.SCR.LZ RZ, R7, R6, 0x0, 0x5e, 1D, 0x1 ;
/*0680*/ LDC.U8 R8, c[0x3][R6] ;
/*0690*/ SHF.R.S32.HI R10, RZ, 0x6, R9 ;
/*06a0*/ LEA.HI R11, R8.reuse, R5, RZ, 0x1d ;
/*06b0*/ SHF.L.U32 R8, R8, 0x2, RZ ;
/*06c0*/ IMAD R11, R11, R4, 0x20 ;
/*06d0*/ LOP3.LUT R8, R8, 0x1c, RZ, 0xc0, !PT ;
/*06e0*/ IADD3 R8, R11, R8, RZ ;
/*06f0*/ IMAD R7, R7, R10, RZ ;
/*0700*/ I2FP.F32.S32 R7, R7 ;
/*0710*/ FMUL R7, R7, 0.00390625 ;
/*0720*/ STS [R8], R7 ;
.L_x_53:
/*0730*/ BSYNC B0 ;
.L_x_52:
/*0740*/ IADD3 R5, R0.reuse, R5, RZ ;
/*0750*/ BAR.SYNC 0x0 ;
/*0760*/ IMAD R15, R5, 0x24, RZ ;
/*0770*/ LEA R18, R0, R3, 0x3 ;
/*0780*/ LDS R4, [R15+0x28] ;
/*0790*/ LDS R5, [R15+0x38] ;
/*07a0*/ LDS R10, [R15+0x34] ;
/*07b0*/ LDS R11, [R15+0x3c] ;
/*07c0*/ LDS R6, [R15+0x20] ;
/*07d0*/ LDS R7, [R15+0x30] ;
/*07e0*/ LDS R13, [R15+0x2c] ;
/*07f0*/ LDS R14, [R15+0x24] ;
/*0800*/ FADD R4, R4, -R5 ;
/*0810*/ FFMA R9, R5.reuse, 1.4142134189605712891, R4.reuse ;
/*0820*/ FFMA R4, R5, 1.4142134189605712891, -R4 ;
/*0830*/ FADD R12, R10, -R11 ;
/*0840*/ FMUL R9, R9, 0.46193981170654296875 ;
/*0850*/ FADD R8, R6.reuse, -R7.reuse ;
/*0860*/ FADD R6, R6, R7 ;
/*0870*/ FADD R5, R12, -R13.reuse ;
/*0880*/ FADD R10, -R10, R13 ;
/*0890*/ FFMA R7, R6.reuse, 0.35355341434478759766, -R9.reuse ;
/*08a0*/ FFMA R6, R6, 0.35355341434478759766, R9 ;
/*08b0*/ FADD R9, R5, R14 ;
/*08c0*/ FFMA R13, R10.reuse, 0.70710682868957519531, -R11.reuse ;
/*08d0*/ FFMA R10, R10, 0.70710682868957519531, R11 ;
/*08e0*/ FMUL R5, R4, 0.19134169816970825195 ;
/*08f0*/ FFMA R11, R12.reuse, 1.4142134189605712891, R9.reuse ;
/*0900*/ FFMA R12, R12, -1.4142134189605712891, R9 ;
/*0910*/ FFMA R4, R8, 0.35355341434478759766, -R5 ;
/*0920*/ FFMA R14, R10, -2.6131260395050048828, R11 ;
/*0930*/ FFMA R5, R8, 0.35355341434478759766, R5 ;
/*0940*/ FFMA R8, R13.reuse, -1.0823919773101806641, R12.reuse ;
/*0950*/ FFMA R11, R10, 2.6131260395050048828, R11 ;
/*0960*/ FFMA R9, R14.reuse, 0.097545139491558074951, R7.reuse ;
/*0970*/ FFMA R14, R14, -0.097545139491558074951, R7 ;
/*0980*/ FFMA R13, R13, 1.0823919773101806641, R12 ;
/*0990*/ FFMA R7, R8.reuse, 0.27778509259223937988, R5.reuse ;
/*09a0*/ FFMA R8, R8, -0.27778509259223937988, R5 ;
/*09b0*/ FFMA R5, R11.reuse, 0.49039259552955627441, R6.reuse ;
/*09c0*/ FFMA R11, R11, -0.49039259552955627441, R6 ;
/*09d0*/ FFMA R6, R13.reuse, 0.41573479771614074707, R4.reuse ;
/*09e0*/ FFMA R4, R13, -0.41573479771614074707, R4 ;
/*09f0*/ STS [R15+0x2c], R9 ;
/*0a00*/ STS [R15+0x30], R14 ;
/*0a10*/ STS [R15+0x28], R7 ;
/*0a20*/ STS [R15+0x34], R8 ;
/*0a30*/ STS [R15+0x20], R5 ;
/*0a40*/ STS [R15+0x24], R6 ;
/*0a50*/ STS [R15+0x38], R4 ;
/*0a60*/ STS [R15+0x3c], R11 ;
/*0a70*/ BAR.SYNC 0x0 ;
/*0a80*/ LDS R7, [R2+0xb4] ;
/*0a90*/ LDS R8, [R2+0xfc] ;
/*0aa0*/ LDS R10, [R2+0x48] ;
/*0ab0*/ LDS R13, [R2+0xd8] ;
/*0ac0*/ LDS R5, [R2+0x6c] ;
/*0ad0*/ LDS R14, [R2+0x24] ;
/*0ae0*/ LDS R9, [R2] ;
/*0af0*/ LDS R12, [R2+0x90] ;
/*0b00*/ S2R R11, SR_CTAID.X ;
/*0b10*/ S2R R4, SR_CTAID.Y ;
/*0b20*/ FADD R6, R7, -R8 ;
/*0b30*/ FADD R10, R10, -R13 ;
/*0b40*/ IMAD R16, R11, 0x8, R0 ;
/*0b50*/ FADD R11, R6, -R5.reuse ;
/*0b60*/ FADD R7, -R7, R5 ;
/*0b70*/ LEA R4, R4, R3, 0x3 ;
/*0b80*/ FFMA R3, R13, 1.4142134189605712891, -R10 ;
/*0b90*/ FADD R11, R11, R14 ;
/*0ba0*/ FFMA R10, R13, 1.4142134189605712891, R10 ;
/*0bb0*/ ISETP.GE.AND P0, PT, R4, c[0x0][0x170], PT ;
/*0bc0*/ FMUL R3, R3, 0.19134169816970825195 ;
/*0bd0*/ FFMA R13, R6, -1.4142134189605712891, R11.reuse ;
/*0be0*/ FMUL R10, R10, 0.46193981170654296875 ;
/*0bf0*/ FADD R0, R9.reuse, -R12.reuse ;
/*0c00*/ FADD R9, R9, R12 ;
/*0c10*/ FFMA R12, R7.reuse, 0.70710682868957519531, -R8.reuse ;
/*0c20*/ FFMA R7, R7, 0.70710682868957519531, R8 ;
/*0c30*/ FFMA R6, R6, 1.4142134189605712891, R11 ;
/*0c40*/ SHF.L.U32 R16, R16, 0x3, RZ ;
/*0c50*/ FFMA R5, R0.reuse, 0.35355341434478759766, -R3.reuse ;
/*0c60*/ FFMA R0, R0, 0.35355341434478759766, R3 ;
/*0c70*/ FFMA R11, R12, -1.0823919773101806641, R13.reuse ;
/*0c80*/ FFMA R3, R9, 0.35355341434478759766, -R10 ;
/*0c90*/ FFMA R8, R7, -2.6131260395050048828, R6 ;
/*0ca0*/ ISETP.GE.OR P0, PT, R16, c[0x0][0x16c], P0 ;
/*0cb0*/ FFMA R9, R9, 0.35355341434478759766, R10 ;
/*0cc0*/ FFMA R12, R12, 1.0823919773101806641, R13 ;
/*0cd0*/ FFMA R6, R7, 2.6131260395050048828, R6 ;
/*0ce0*/ FFMA R13, R11.reuse, 0.27778509259223937988, R0.reuse ;
/*0cf0*/ FFMA R17, R11, -0.27778509259223937988, R0 ;
/*0d00*/ FFMA R11, R8.reuse, 0.097545139491558074951, R3.reuse ;
/*0d10*/ FFMA R15, R8, -0.097545139491558074951, R3 ;
/*0d20*/ FFMA R7, R12, 0.41573479771614074707, R5 ;
/*0d30*/ FFMA R3, R6, 0.49039259552955627441, R9 ;
/*0d40*/ FFMA R5, R12, -0.41573479771614074707, R5 ;
/*0d50*/ FFMA R9, R6, -0.49039259552955627441, R9 ;
/*0d60*/ STS [R2+0x48], R13 ;
/*0d70*/ STS [R2+0xb4], R17 ;
/*0d80*/ STS [R2+0x6c], R11 ;
/*0d90*/ STS [R2+0x90], R15 ;
/*0da0*/ STS [R2+0x24], R7 ;
/*0db0*/ STS [R2+0xd8], R5 ;
/*0dc0*/ STS [R2], R3 ;
/*0dd0*/ STS [R2+0xfc], R9 ;
/*0de0*/ BAR.SYNC 0x0 ;
/*0df0*/ @P0 EXIT ;
/*0e00*/ IMAD R18, R18, 0x24, RZ ;
/*0e10*/ ULDC.64 UR4, c[0x0][0x118] ;
/*0e20*/ LDS R2, [R18+0x24] ;
/*0e30*/ LDS R0, [R18+0x20] ;
/*0e40*/ LDS R7, [R18+0x30] ;
/*0e50*/ LDS R9, [R18+0x34] ;
/*0e60*/ LDS R10, [R18+0x38] ;
/*0e70*/ LDS R3, [R18+0x28] ;
/*0e80*/ LDS R6, [R18+0x2c] ;
/*0e90*/ LDS R12, [R18+0x3c] ;
/*0ea0*/ FADD R2, R2, 128 ;
/*0eb0*/ FADD R0, R0, 128 ;
/*0ec0*/ FMNMX R2, RZ, R2, !PT ;
/*0ed0*/ FADD R7, R7, 128 ;
/*0ee0*/ FMNMX R0, RZ, R0, !PT ;
/*0ef0*/ FMNMX R2, R2, 255, PT ;
/*0f00*/ FADD R9, R9, 128 ;
/*0f10*/ FMNMX R8, RZ, R7, !PT ;
/*0f20*/ FMNMX R0, R0, 255, PT ;
/*0f30*/ FADD R11, R10, 128 ;
/*0f40*/ FMNMX R9, RZ, R9, !PT ;
/*0f50*/ F2I.NTZ R5, R2 ;
/*0f60*/ FMNMX R8, R8, 255, PT ;
/*0f70*/ FADD R3, R3, 128 ;
/*0f80*/ FMNMX R10, R9, 255, PT ;
/*0f90*/ FADD R6, R6, 128 ;
/*0fa0*/ FMNMX R3, RZ, R3, !PT ;
/*0fb0*/ F2I.NTZ R0, R0 ;
/*0fc0*/ FMNMX R2, RZ, R11, !PT ;
/*0fd0*/ FADD R9, R12, 128 ;
/*0fe0*/ FMNMX R3, R3, 255, PT ;
/*0ff0*/ FMNMX R12, R2, 255, PT ;
/*1000*/ FMNMX R6, RZ, R6, !PT ;
/*1010*/ F2I.NTZ R8, R8 ;
/*1020*/ FMNMX R2, RZ, R9, !PT ;
/*1030*/ FMNMX R6, R6, 255, PT ;
/*1040*/ FMNMX R14, R2, 255, PT ;
/*1050*/ F2I.NTZ R11, R10 ;
/*1060*/ LEA R0, R5, R0, 0x8 ;
/*1070*/ F2I.NTZ R7, R3 ;
/*1080*/ F2I.NTZ R13, R12 ;
/*1090*/ IMAD R3, R4, c[0x0][0x168], RZ ;
/*10a0*/ LEA R8, R11, R8, 0x8 ;
/*10b0*/ SHF.R.S32.HI R4, RZ, 0x1f, R16.reuse ;
/*10c0*/ IADD3 R2, P0, P1, R3, c[0x0][0x160], R16 ;
/*10d0*/ F2I.NTZ R9, R6 ;
/*10e0*/ SHF.R.S32.HI R3, RZ, 0x1f, R3 ;
/*10f0*/ LEA R0, R7, R0, 0x10 ;
/*1100*/ IADD3.X R3, R3, c[0x0][0x164], R4, P0, P1 ;
/*1110*/ F2I.NTZ R15, R14 ;
/*1120*/ LEA R8, R13, R8, 0x10 ;
/*1130*/ LEA R4, R9, R0, 0x18 ;
/*1140*/ LEA R5, R15, R8, 0x18 ;
/*1150*/ STG.E.64 [R2.64], R4 ;
/*1160*/ EXIT ;
.L_x_57:
/*1170*/ BRA `(.L_x_57);
/*1180*/ NOP;
/*1190*/ NOP;
/*11a0*/ NOP;
/*11b0*/ NOP;
/*11c0*/ NOP;
/*11d0*/ NOP;
/*11e0*/ NOP;
/*11f0*/ NOP;
.L_x_61:At a glance, jpegparse_pass1 seems to be the simplest
kernel, with jpegparse_pass2 containing a similar amount of
instructions but a more complicated logical flow.
jpegdec_idct looks very arithmetic-intensive, containing
very few nodes, while jpegdec_vld is by far the most
logically complex kernel.
Decompilation
After completing this initial, high-level analysis, I moved on to
examining the raw SASS code. While the process was tedious and lengthy,
there are in fact few different instructions being used in a normal CUDA
kernel. Once I became familiar with the assembler’s general structure,
my pace improved, and I began to recognize patterns more
intuitively.
My method was simply to translate each instruction into its GLSL
equivalent, line by line. When I could notice a pattern, such as a loop
or a branch, I would try to reproduce the logic in “natural” code. After
a while, the flow of the kernel starts appearing, until a complete
understanding is achieved.
Throughout this work, I found Compiler Explorer to be
extremely useful for testing decompiled patterns. Since NVIDIA provides
documentation for their PTX
intermediate assembler language, you can explore the mapping to SASS
instructions by writing a small PTX snippet using inline assembly, and
validate your assumptions.
jpegparse_pass1
The first kernel I took a detailed look at is
jpegparse_pass1, for two reasons. First, its control flow
appeared relatively simple. Second, I was reasonably confident that it
operated directly on the raw JPEG bitstream without additional metadata,
reducing the need for speculation during reverse engineering.
Below is my manual decompilation of this kernel. Note that I haven’t
made sure all edge case handling was reproduced correctly, the goal is
to illustrate the core algorithm.
The assembly is also translated to GLSL instead of CUDA because that’s
what I’m ultimately more interested in.
layout(local_size_x = 0x100) in;
shared int smem[0x100];
void main(uint8_t *data_in, uint64_t *data_out, int size) {
// Initialise state
int thread_sz = max((size + 0xffff) >> 0x10, 4);
int bitstream_off = (gl_WorkGroupID.x * 0x100 + gl_LocalInvocationID.x) * thread_sz;
int bitstream_end = min(bitstream_off + thread_sz, size - 1);
int first_mcu_off = 0, num_mcus = ((gl_WorkGroupID.x | gl_LocalInvocationID.x) != 0) ? 0 : 1;
// Scan stream for restart markers
int prev;
for (int i = bitstream_off; i < bitstream_end & ~3; i += 4) {
int a = data_in[i+0], b = data_in[i+1], c = data_in[i+2], d = data_in[i+3];
if (prev == 0xff && (a & 0xf8) == 0xd0) {
if (!num_mcus) first_mcu_off = i + 1;
++num_mcus;
}
if (a == 0xff && (b & 0xf8) == 0xd0) {
if (!num_mcus) first_mcu_off = i + 2;
++num_mcus;
}
if (b == 0xff && (c & 0xf8) == 0xd0) {
if (!num_mcus) first_mcu_off = i + 3;
++num_mcus;
}
if (c == 0xff && (d & 0xf8) == 0xd0) {
if (!num_mcus) first_mcu_off = i + 4;
++num_mcus;
}
prev = d;
}
for (int i = bitstream_end & ~3; i < bitstream_end; ++i) {
int a = data_in[i];
if (prev == 0xff && (a & 0xf8) == 0xd0) {
if (!num_mcus) first_mcu_off = i + 1;
++num_mcus;
}
prev = a;
}
smem[gl_LocalInvocationID.x] = num_mcus;
// Inclusive prefix sum
for (int i = 0; i < 8; ++i) {
barrier();
int n = 1 << i;
if (gl_LocalInvocationID.x & n)
smem[gl_LocalInvocationID.x] += smem[(gl_LocalInvocationID.x & ~n) | (n - 1)];
}
// Store to output
data_out[gl_WorkGroupID.x * 0x100 + gl_LocalInvocationID.x] =
smem[gl_LocalInvocationID.x] | (first_mcu_off << 32);
}What this kernel does is first divide the input JPEG bitstream in
equal parts, between all 65536 threads. Each thread looks through its
slice of data for restart markers, which are denoted in the stream by a
FFD0-7 sequence. Upon finding a marker, the thread
increments a counter representing the number of MCU sequences within its
slice of the bitstream, and also remembers the location of the first
encountered
marker.Special
casing is given for the first thread, since the initial MCU doesn’t
start with a marker. The thread then writes the MCU counter to
shared memory.
Interestingly, this search has been “vectorised” to read 4 bytes of the
stream at a time (with a cleanup loop to handle the remaining unaligned
bytes). This probably improves memory access patterns.
After this, the threads perform an inclusive prefix sum over the MCU
counters. This is done using the Sklansky
algorithm,Sklansky,
J. “Conditional-Sum Addition Logic.” IEEE Transactions on Electronic
Computers EC-9, no. 2 (June 1960): 226–31. (link) in a
loop with 8 iterations (summing over 256 values). This strategy will
enable half the threads in each iteration, forming a “block” (patterned
in blue in the figure below). Each thread within the block adds the
value of the thread immediately left of the block to its own.
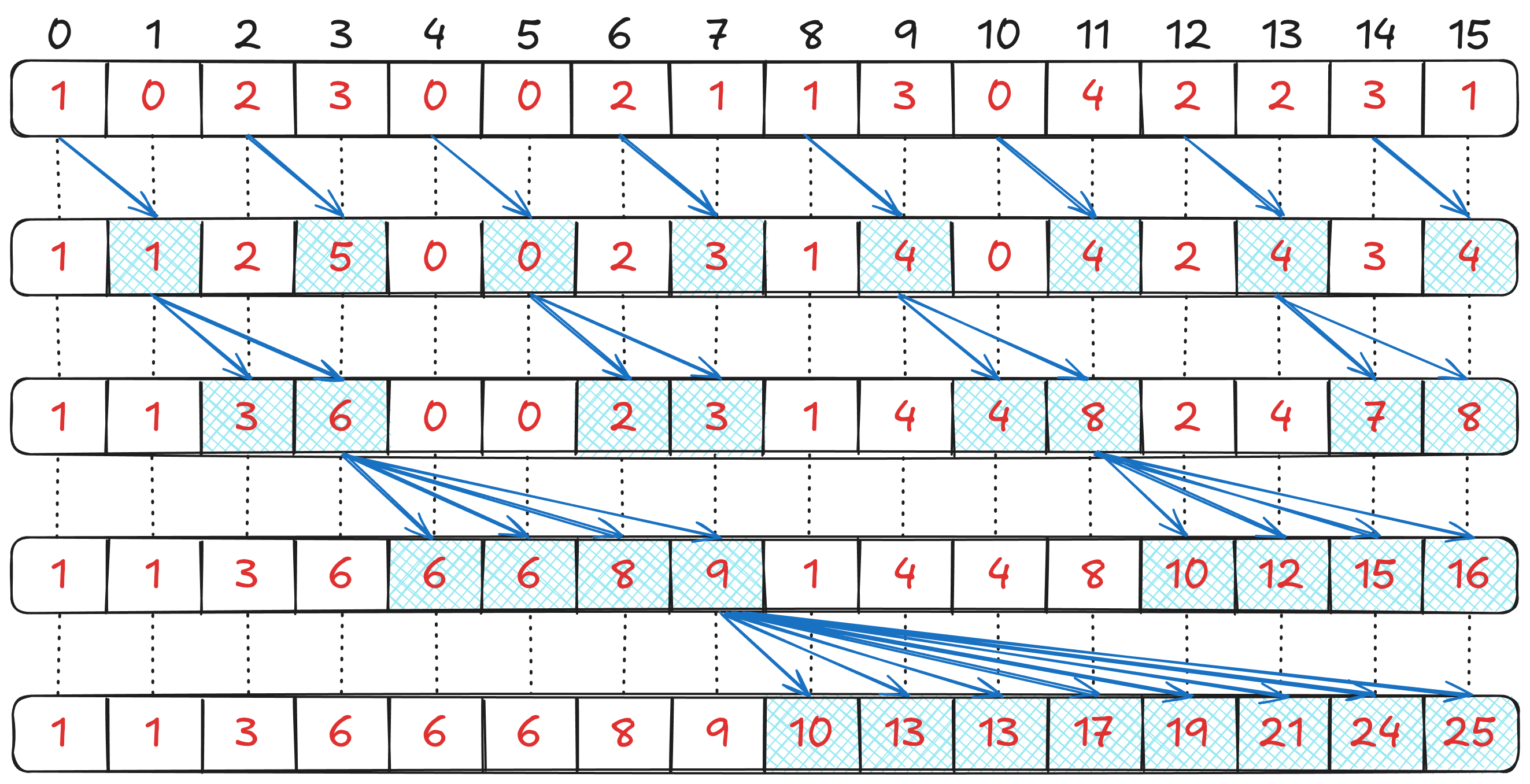 Figure
2: Inclusive prefix sum for 16 values using the Sklansky algorithm, in 4
iterations.
Figure
2: Inclusive prefix sum for 16 values using the Sklansky algorithm, in 4
iterations.
Enabled threads are patterned in blue at each
iteration.
Finally, the thread writes its summed MCU count, and the bitstream position of its first MCU in the output stream.
jpegdec_idct
The second kernel I reverse engineered was jpegdec_idct.
This time, I was actually interested in the GPU programming techniques
used to improve the speed of the iDCT operation. Indeed, since the iDCT
is inherently parallelisable, there is more room for advanced
optimisation work.
From the grid size observed in Nsight
systems and the size of the picture, we know the kernel outputs
samples per block. From the block size
(),
we can guess each thread outputs a line of
samples, though we will need to verify this from the decompilation.
My reverse engineering of the code, still in pseudo-GLSL, is given below:
layout(local_size_x = 0x40) in;
// Total shared mem usage: 2336 bytes
shared int vld_res[8]; // Offset 0x00
shared float blocks[0x40][8+1]; // Offset 0x20
layout(r32i) uniform sampler1D vld_tex;
// JPEG zigzag order
uint8_t jpeg_natural_order[] = {
0, 1, 8, 16, 9, 2, 3, 10, 17, 24, 32, 25, 18, 11, 4, 5, // 0x10080100, 0x0a030209, 0x19201811, 0x05040b12,
12, 19, 26, 33, 40, 48, 41, 34, 27, 20, 13, 6, 7, 14, 21, 28, // 0x211a130c, 0x22293028, 0x060d141b, 0x1c150e07,
35, 42, 49, 56, 57, 50, 43, 36, 29, 22, 15, 23, 30, 37, 44, 51, // 0x38312a23, 0x242b3239, 0x170f161d, 0x332c251e,
58, 59, 52, 45, 38, 31, 39, 46, 53, 60, 61, 54, 47, 55, 62, 63, // 0x2d343b3a, 0x2e271f26, 0x363d3c35, 0x3f3e372f,
};
void idct(int idx1, int step1, int idx2, int step2) {
float c0 = blocks[idx1 + 0*step1][idx2 + 0*step2];
float c1 = blocks[idx1 + 1*step1][idx2 + 1*step2];
float c2 = blocks[idx1 + 2*step1][idx2 + 2*step2];
float c3 = blocks[idx1 + 3*step1][idx2 + 3*step2];
float c4 = blocks[idx1 + 4*step1][idx2 + 4*step2];
float c5 = blocks[idx1 + 5*step1][idx2 + 5*step2];
float c6 = blocks[idx1 + 6*step1][idx2 + 6*step2];
float c7 = blocks[idx1 + 7*step1][idx2 + 7*step2];
float tmp1 = c6 * 1.4142134189605712891 + (c2 - c6);
float tmp2 = c6 * 1.4142134189605712891 - (c2 - c6);
float a1 = (c0 + c4) * 0.35355341434478759766 + tmp1 * 0.46193981170654296875;
float a4 = (c0 + c4) * 0.35355341434478759766 - tmp1 * 0.46193981170654296875;
float a3 = (c0 - c4) * 0.35355341434478759766 + tmp2 * 0.19134169816970825195;
float a2 = (c0 - c4) * 0.35355341434478759766 - tmp2 * 0.19134169816970825195;
float tmp3 = (c3 - c5) * 0.70710682868957519531 + c7;
float tmp4 = (c3 - c5) * 0.70710682868957519531 - c7;
float tmp5 = (c5 - c7) * 1.4142134189605712891 + (c5 - c7) + (c1 - c3);
float tmp6 = (c5 - c7) * -1.4142134189605712891 + (c5 - c7) + (c1 - c3);
float m1 = tmp3 * 2.6131260395050048828 + tmp5;
float m4 = tmp3 * -2.6131260395050048828 + tmp5;
float m2 = tmp4 * 1.0823919773101806641 + tmp6;
float m3 = tmp4 * -1.0823919773101806641 + tmp6;
blocks[idx1 + 0*step1][idx2 + 0*step2] = m1 * 0.49039259552955627441 + a1;
blocks[idx1 + 7*step1][idx2 + 7*step2] = m1 * -0.49039259552955627441 + a1;
blocks[idx1 + 1*step1][idx2 + 1*step2] = m2 * 0.41573479771614074707 + a2;
blocks[idx1 + 6*step1][idx2 + 6*step2] = m2 * -0.41573479771614074707 + a2;
blocks[idx1 + 2*step1][idx2 + 2*step2] = m3 * 0.27778509259223937988 + a3;
blocks[idx1 + 5*step1][idx2 + 5*step2] = m3 * -0.27778509259223937988 + a3;
blocks[idx1 + 3*step1][idx2 + 3*step2] = m4 * 0.097545139491558074951 + a4;
blocks[idx1 + 4*step1][idx2 + 4*step2] = m4 * -0.097545139491558074951 + a4;
}
int clamp_coeff(float c) {
return int(clamp(c0 + 128.0f, 0.0f, 255.0f));
}
void main(void *out, int stride, int width, int height, int vld_meta_w) {
int lid = gl_LocalInvocationID.x;
uvec3 wid = gl_WorkGroupID;
// Load entropy decoding metadata
if ((lid & 7) == 0) {
int tex_pos = wid.y * vld_meta_w + (lid>>3) + (wid.x<<3);
vld_res[lid>>3] = texelFetch(vld_tex, tex_pos, 0).r;
}
// Clear DCT blocks
blocks[(lid & ~7)+0][lid & 7] = 0;
blocks[(lid & ~7)+1][lid & 7] = 0;
blocks[(lid & ~7)+2][lid & 7] = 0;
blocks[(lid & ~7)+3][lid & 7] = 0;
blocks[(lid & ~7)+4][lid & 7] = 0;
blocks[(lid & ~7)+5][lid & 7] = 0;
blocks[(lid & ~7)+6][lid & 7] = 0;
blocks[(lid & ~7)+7][lid & 7] = 0;
barrier();
// Load DCT coeffs from global to shared memory, perform inverse quantization
uint vld = vld_res[lid>>3];
uint num_dct_coeffs = vld & 0x3f, off = vld >> 6, pos = tid & 7;
if (off != 0 && pos <= num_dct_coeffs) {
// Loop head, single load
uint v = texelFetch(vld_tex, pos + off, 0).r;
uint idx = v & 0x3f;
uint coeff = v >> 6;
uint q = texelFetch(vld_tex, idx, 0).r;
uint scan = jpeg_natural_order[idx];
blocks[(lid & ~7) + (scan>>3)][scan & 7] = (float)(q * coeff) * 0.00390625;
pos += 8;
// Loop body, double load
if (pos <= num_dct_coeffs && (num_dct_coeffs - pos) >= 7) {
do {
uint v1 = texelFetch(vld_tex, pos + off + 0, 0).r;
uint v2 = texelFetch(vld_tex, pos + off + 8, 0).r;
uint idx1 = v1 & 0x3f, idx2 = v2 & 0x3f;
uint coeff1 = v1 >> 6, coeff2 = v2 >> 6;
uint q1 = texelFetch(vld_tex, idx1, 0).r;
uint q2 = texelFetch(vld_tex, idx2, 0).r;
uint scan1 = jpeg_natural_order[idx1];
uint scan2 = jpeg_natural_order[idx2];
blocks[(lid & ~7) + (scan1>>3)][scan1 & 7] = (float)(q1 * coeff1) * 0.00390625;
blocks[(lid & ~7) + (scan2>>3)][scan2 & 7] = (float)(q2 * coeff2) * 0.00390625;
pos += 0x10;
} while (pos < num_dct_coeffs - 7);
}
// Loop tail, single load
if (pos <= num_dct_coeffs) {
v = texelFetch(vld_tex, pos + off, 0).r;
idx = v & 0x3f;
coeff = v >> 6;
q = texelFetch(vld_tex, idx, 0).r;
scan = jpeg_natural_order[idx];
blocks[(lid & ~7) + (scan>>3)][scan & 7] = (float)(q * coeff) * 0.00390625;
}
}
barrier();
// Row-wise IDCT
idct(lid, 0, 0, 1);
barrier();
// Column-wise IDCT
idct(lid & ~7, 1, lid & 7, 0);
barrier();
// Exit if out of bounds
int x = (wid.x << 3) + (lid & 7) << 3,
y = (wid.y << 3) + (lid >> 3);
if (x >= width || y >= height)
return;
// Rescale, clamp and write to output
float c0 = blocks[(lid & 7 << 3) + (lid >> 3)][0];
float c1 = blocks[(lid & 7 << 3) + (lid >> 3)][1];
float c2 = blocks[(lid & 7 << 3) + (lid >> 3)][2];
float c3 = blocks[(lid & 7 << 3) + (lid >> 3)][3];
float c4 = blocks[(lid & 7 << 3) + (lid >> 3)][4];
float c5 = blocks[(lid & 7 << 3) + (lid >> 3)][5];
float c6 = blocks[(lid & 7 << 3) + (lid >> 3)][6];
float c7 = blocks[(lid & 7 << 3) + (lid >> 3)][7];
uint *o = out + y * stride + x;
*(o + 0) = (clamp_coeff(c0) << 0) | (clamp_coeff(c1) << 8) |
(clamp_coeff(c2) << 16) | (clamp_coeff(c3) << 24);
*(o + 1) = (clamp_coeff(c4) << 0) | (clamp_coeff(c5) << 8) |
(clamp_coeff(c6) << 16) | (clamp_coeff(c7) << 24);
}The shader processes 8 8x8 blocks, and uses shared memory to hold a
dword per block, and the blocks themselves. The block space is padded to
avoid bank
conflicts (see the 8+1 in the declaration).
Each thread (“work-item” in Vulkan-speak) processes 8 coefficients,
meaning a group of 8 thread manages a block. This is visible
inparticular from the various masking calculations scattered around the
code (lid & 7
and so on).
The kernel takes a 5 arguments representing the output memory and
dimensions. It also reads from a texture for various data, including the
quantization matrix, metadata regarding DCT coefficients for each block,
and the DCT coefficients themselves. In order to (presumably) save on
memory, only non-zero coefficients are included.
The program flow is as follows:
- The kernel begins by loading metadata regarding entropy decoding
(VLD for variable-length decoding) results for the block. Only the
leading thread participates, reading an
intfrom the VLD texture and storing it to shared memory. - Each thread then reads its corresponding value, which encodes the number of DCT coefficients and the offset of the first coefficient within the VLD texture.
- DCT coefficients are read from the VLD texture and stored in shared
memory, 8 at a
time.These
8 integer reads are sequential, meaning they form a single 256-bit
memory transaction. This is important for coalescing
global memory accesses. The coefficients are encoded similarly to
the metadata before, where each
intcontains the coefficient value and its index inside the block. This index is used to read the corresponding inverse quantization coefficient.There seems to be a straightforward possible optimization here: the quantization matrix is always read from the texture, instead of storing it in shared/constant memory for quicker access. It would also be possible to write it in the block padding mentionned above. The loop is partially unrolled: when possible, the main loop body merges two iterations. - DCT coefficients are dequantized by multiplying with the quantization coeffients, then converted to float and multiplied by 0.00390625 (1/256).I’m not certain about this value. It might be intended for exact float conversion of integer DCT coefficients, though JPEG usually uses 11-bit signed integers internally.
- The inverse transform is performed. This is done using an unscaled, 8-point, 1-dimensional IDCT across rows then columns, using the well-know separability properties of the 2D transform.
- The resulting spatial values are rescaled (really, just offset by 128), clamped to an 8-bit range, converted to integers and stored in the final surface. Each thread stores a line of 8 pixels.
The IDCT routine itself is quite interesting. It obviously uses the
symmetry properties of the transform to reduce the total number of
operations, and pre-computes trigonometric constants. These constants
are encoded as immediate values in the instruction stream. The function
is similar to the one found here,
though slightly more optimized.
The calculation happens entirely in registers, besides the initial load
and final write. The compiler seems to try very hard at maximizing
FFMA (fused multiply-add) instruction usage, to increase
throughput, even sometimes duplicating work. It would be interesting to
see how it compares to the “classic” AAN IDCT implementation (see for
instance here),
which removes most of the multiplies by folding them into the final
rescaling.
Another possibility would be to use packed fp16 instructions, which seem
like a good fit, in particular for the symmetric multiplications.
The constants used throughout the IDCT routine can be easily figured out once you know what to look for (ie. combinations of square roots and cosines). I automated the search with the following script:
fact = np.sqrt(np.r_[range(1, 9)])
trig = np.cos(np.r_[range(16)] * np.pi / 16)
m1, m2 = np.outer(fact, trig), np.outer(1/fact, trig)
def find_constant(c, thres=1e-6):
if (t := np.abs(c - m1) < thres).any():
for s, f in zip(*t.nonzero()):
print(f"sqrt({s+1}) * cos({f}*pi/16)")
if (t := np.abs(c - m2) < thres).any():
for s, f in zip(*t.nonzero()):
print(f"1/sqrt({s+1}) * cos({f}*pi/16)")
constants = {0.35355341434478759766, 1.4142134189605712891, 0.46193981170654296875,
0.19134169816970825195, 0.70710682868957519531, 2.6131260395050048828,
1.0823919773101806641, 0.49039259552955627441, 0.41573479771614074707,
0.27778509259223937988, 0.097545139491558074951}
for c in constants:
print(c)
find_constant(c)Which yields the following results (after simplification):
| Constant | Expression |
|---|---|
| 0.3535534143447876 | |
| 1.4142134189605713 | |
| 0.46193981170654297 | |
| 0.19134169816970825 | |
| 0.7071068286895752 | |
| 2.613126039505005 | |
| 1.0823919773101807 | |
| 0.4903925955295563 | |
| 0.41573479771614075 | |
| 0.2777850925922394 | |
| 0.09754513949155807 |
I found that the minimum threshold on tolerance applicable during the search was . This is a pretty low accuracy even for single-precision floats, and leads me to think the constants were precomputed and hardcoded in the CUDA source, rather than being constant-folded by the compiler at compile time.